
Tesla元AI責任者でOpenAI共同創業者のAndrej Karpathyが、Claude 4.5のリリースについて「11月のClaude 3.5と同等の次元の進化」と自身のX(旧Twitter)に投稿し、AI界隈で大きな話題を呼んでいます。ベンチマーク数値で優位に立つことは珍しくなくなりましたが、Karpathyが強調したのは数字だけではなく「質的な手応え」でした。この記事では、その発言の背景にある技術的文脈と、普段AIをビジネスに使っている会社員にとっての実際の意味を整理します。
Karpathyが「質的な進化」と表現した意味
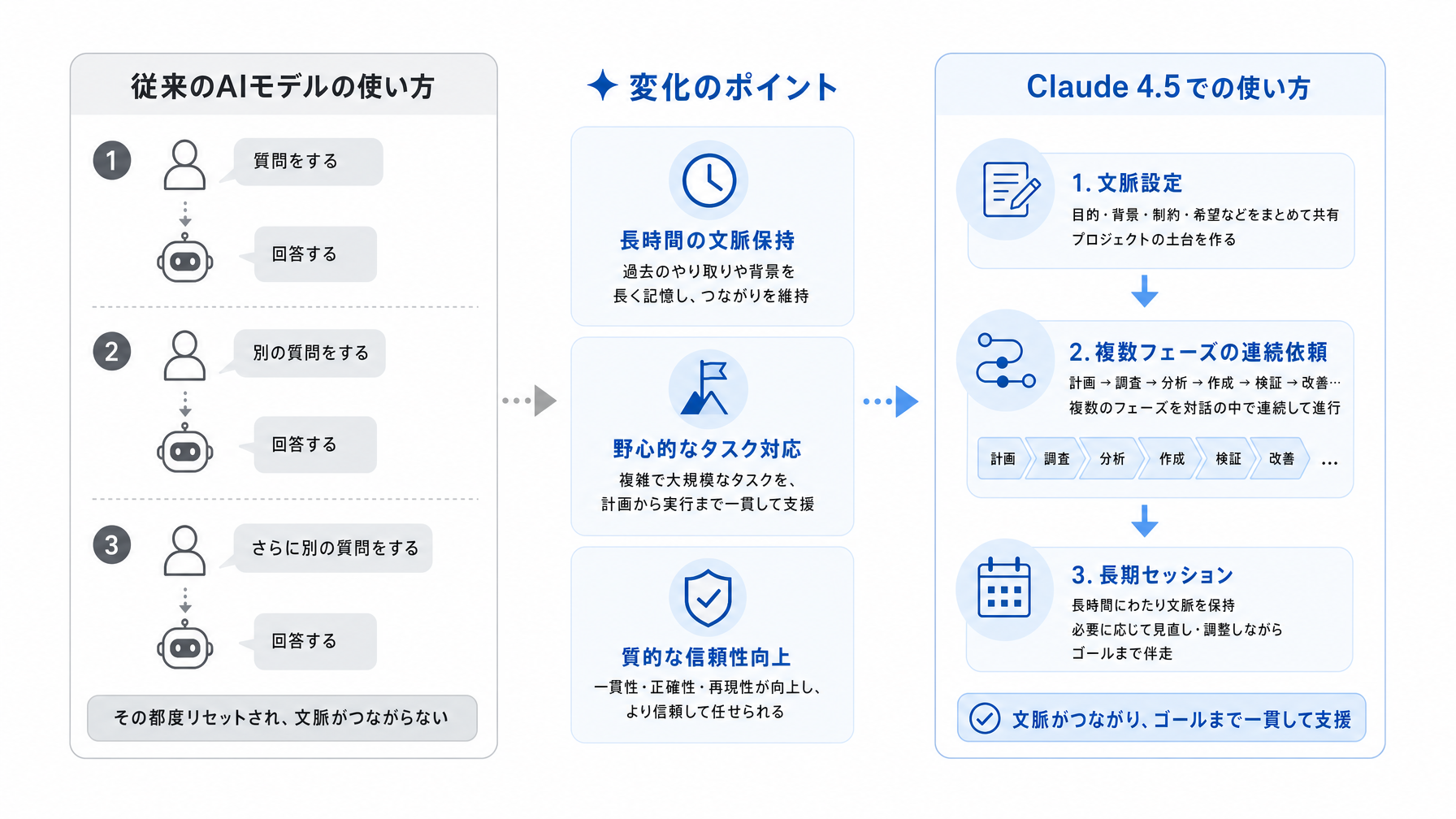
AIの新モデルが出るたびに「SOTA(最先端)」という言葉が飛び交いますが、Karpathyの投稿が注目されたのは、ベンチマーク評価の先を指摘したからです。彼は「長時間にわたる難問のセッションで特に際立つ」と述べており、これは短い1問1答ではなく、複雑な問題を連続的に掘り下げていくような使い方を想定した言葉です。従来のモデルは、会話が長くなるにつれて文脈を見失ったり、途中で結論を急いだりする傾向がありました。Claude 4.5ではその問題が大きく改善されているという手応えが、「モデルが『問題を把握している』と感じられる」という表現に凝縮されています。これはつまり、単に賢いだけでなく、複雑な仕事を一緒に進めるパートナーとしての信頼性が上がったという意味として受け取れます。
「Claude Fable 5 = Mythos+安全対策」という構造
Karpathyの投稿では、Claude 4.5の元となるモデルを「Mythos」と呼び、それに安全対策(safeguards)を加えたものが一般公開版だと説明しています。このような「研究用モデルと製品版の分離」はAnthropicが以前から採用しているアプローチで、能力を最大化したモデルをそのまま公開するのではなく、有害な出力を抑制するフィルタリングを施した上でリリースするという思想に基づいています。重要なのは、この構造は「安全のために能力を犠牲にしている」わけではなく、「能力を保ちながら安全を上乗せする」設計を目指しているという点です。Anthropicは「Constitutional AI」と呼ばれる独自の安全設計手法を長年研究しており、今回のリリースはその成熟を示す一例と見ることができます。AI企業が安全性を競争優位の軸として打ち出し始めているという業界の流れが、ここにも表れています。
実務で「長時間の難問セッション」がどう変わるか
ここで具体的な場面を考えてみましょう。たとえば40代の事業企画マネージャーが、新規事業の可能性検証をClaude 4.5に依頼するとします。市場環境の整理、競合分析、収益モデルの試算、リスクシナリオの列挙——これらを一連の会話の流れの中でClaude 4.5に担当させると、従来のモデルでは途中から「前の話題を忘れている」感覚を受けることがありました。Claude 4.5では、会話が長くなっても前提条件を保持し、矛盾のない回答を継続できる精度が上がっているとKarpathyは評価しています。もう一つ具体例を挙げると、経理部門の30代スタッフが月次の予算乖離レポートを作成する際、「今月の数字を見せるから原因仮説を立てて」「その仮説に基づいて経営報告用の文章を書いて」「役員から来そうな質問とその回答案も考えて」という3段階の依頼を連続して行う使い方があります。このように段階的に深掘りする作業こそ、Karpathyが言う「長時間の問題解決セッション」に該当します。
ベンチマーク上位という事実をどう受け止めるか
以下は、Claude 4.5が主要ベンチマークでどの位置にいるかを他の主要モデルと比較した概観です(2025年上半期時点の公開情報に基づく概算)。
| モデル | 数学推論 | コーディング | 長文理解 | 総合評価 |
|---|---|---|---|---|
| Claude 4.5 | ◎ | ◎ | ◎ | SOTA |
| GPT-4o | ○ | ○ | ○ | 上位 |
| Gemini 1.5 Pro | ○ | ○ | ◎ | 上位 |
| Llama 3.1 | △ | ○ | △ | 中位 |
数値で「最高」と言われても、実務でどう違うのかがわからなければ意味がありません。ベンチマークが高いモデルが必ずしも自分の仕事に合うとは限らないという視点は持っておくべきです。ただ、Karpathyのような技術的知見のある人物が「質的にも本物の進化」と言い切っているのは、単なるスコアゲーム(ベンチマーク向けに最適化するだけで実用性が低い)ではないことを示すひとつの根拠になります。ChatGPTの使い方ガイドでも触れているように、AIツールの評価は複数の観点から行うのが基本で、一つの指標だけで判断するのは避けたいところです。
「もっと野心的なタスクを渡せる」という変化の本質
Karpathyが投稿の中で「今まで任せていたよりも野心的なタスクを渡せる」と書いているのは、AIツールの使い方そのものが変わるシグナルとして読めます。これまで多くのビジネスパーソンは、AIを「補助的なツール」として使ってきました。文章の誤字を直す、箇条書きを整形する、翻訳を一段階スムーズにする——そういった用途です。しかしClaudeのような高精度モデルが「長い問題をトレースし続けられる」ようになると、担当できる仕事の範囲が変わってきます。もちろん、渡したタスクすべてが完璧に仕上がるわけではなく、確認と修正のプロセスは依然として必要です。ただ、「どこまでAIに委ねられるか」のラインを再設定するきっかけとして、このリリースをとらえるのは自然な考え方だと思います。AIを活用した副業・キャリアシフトのガイドでも取り上げているように、AIに任せる範囲を広げることは、空いた時間をより高度な判断業務に使う機会でもあります。
より良いアウトプットのためにプロンプトをどう変えるか
Claude 4.5が「難しい問題の長時間セッション」で真価を発揮するとすれば、その性能を引き出す使い方も変わってきます。「一問一答で使う」スタイルから、「前提を共有した上で複数のフェーズを連続して依頼する」スタイルへの移行が、より効果的です。たとえば冒頭に「この会話では〇〇のプロジェクト計画を作ります。私の役割は△△で、制約は◻︎◻︎です」と文脈を与えてから始めると、後半の回答の精度が上がりやすいと言われています。プロンプトの書き方ガイドでは文脈の渡し方について詳しく解説していますが、Claude 4.5のような長文理解に強いモデルでは、特に「冒頭の文脈設定が長くなっても大丈夫」という点が重要な変化です。以前のモデルでは長い前置きが後半で無視されることがありましたが、その問題が改善されているなら、プロンプトの設計方針も見直す価値があります。
まとめ
Karpathyの評価が示しているのは、Claude 4.5がスコア上の勝利を超えた「使い心地の変化」を持っているという点です。ベンチマーク競争が日常化した今、信頼できる評者が「質的にも違う」と言い切るのは珍しいことで、それだけ実際に触れてみる価値があるモデルだと判断できます。ただし、どのモデルが自分の仕事に合うかは、最終的には実際に使ってみた体験から判断するしかありません。今週の業務の中で、「少し難しすぎて諦めていたタスク」を一つだけClaude 4.5に投げてみる——それが、この発表を自分ごとにする一番の近道かもしれません。







