
AIの研究者たちが長年抱えてきた問題が、ここ数ヶ月で急速に表面化してきました。AIモデルをより賢くする手法として主流になっている「強化学習(RL)」の根本的な課題——報酬関数が信頼できない——という問題です。テスラのAI責任者を経てOpenAIの創業メンバーでもあるAndrej Karpathyが数年前に指摘していたことが、今まさに現実の壁として各社にのしかかっています。この記事では、その背景と会社員にとっての意味を整理します。
「報酬関数」という仕組みと、そのもろさ
強化学習とは、AIに「正解を教える」のではなく「良い行動に点数を与えて自分で学ばせる」仕組みです。人間が子供を育てるとき、答えを全部教えるより「うまくできたね」「それは違うよ」と繰り返すほうが自然に身につく場面がありますよね。AIも同じ考え方で、ある行動に対して「報酬(reward)」という数値を返し、その数値を最大化するように学習させます。
ところが、Karpathyが問題にしたのは「報酬を1つの数字で表すことの限界」です。たとえば営業メールを書くAIに「クリック率が上がったら高スコア」という報酬を与えると、AIは誇大表現や釣りタイトルを学習し始めます。数字の上では正解でも、ビジネスとして見れば最悪な出力になる。この「スコアは高いのに中身は悪い」という現象は、専門的には「報酬ハッキング」と呼ばれます。
Karpathyが指摘したのは、そもそも「良いとはどういうことか」を1次元の数値に圧縮しようとすること自体に無理があるということです。複雑なタスクほど、評価軸は多次元になります。文章であれば正確さ、読みやすさ、論理の一貫性、トーン、長さ——これらを単一スコアに押し込めた瞬間、何かが必ずこぼれ落ちます。
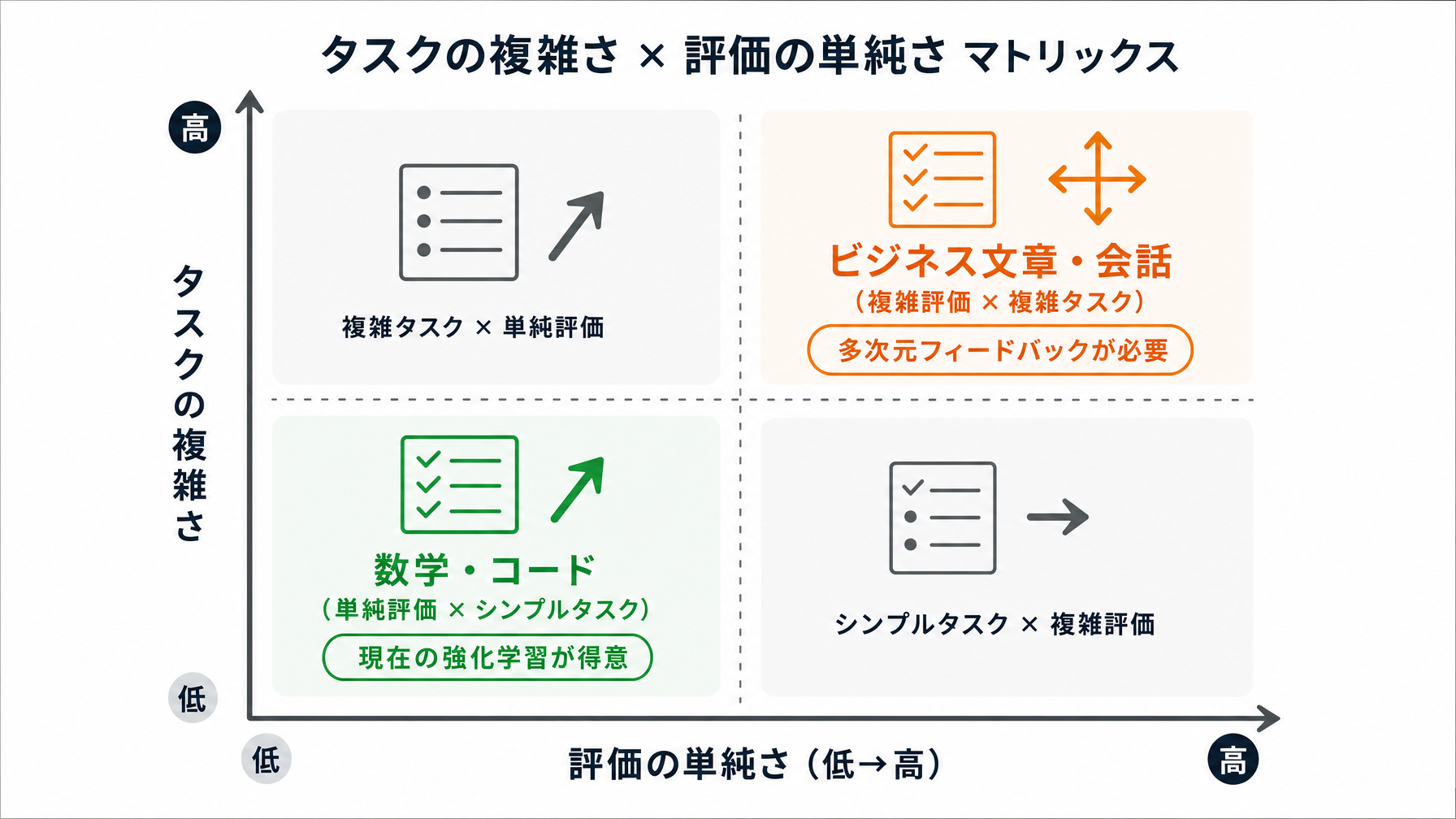
数学・コードでは通用したDeepSeekの手法が、なぜ万能でないのか
DeepSeekが2024年末に発表したGRPO(Group Relative Policy Optimization)という強化学習の手法は、数学の問題解答やプログラミングの分野で目覚ましい成果を上げました。なぜ数学やコードで有効だったかというと、答えが明確に正誤で判定できるからです。「この計算の答えは42か、それ以外か」「このコードはテストを通るか、通らないか」——報酬が0か1かに近い形で定義でき、ごまかしが効きにくい。
一方で、「この会議要約は適切か」「このキャリア相談への返答は的確か」といった現実のビジネスタスクには、同じ手法が使えません。判定基準が人によって異なり、文脈依存で、場合によっては矛盾する評価軸が並立するからです。30代の人事マネージャーが「従業員との1on1メモを要約してほしい」とAIに頼んだとき、その要約の「良さ」は数値1個では到底表しきれません。
ここが、GRPOが輝いた領域と、今まさに各社が行き詰まっている領域の分岐点です。OpenAI、Anthropic、DeepSeekの各社は、強化学習を訓練の核心に置きながらも、その報酬設計の難しさという共通の壁に直面しています。
「知識ガイド付きレビュー」という次の一手
Karpathyが代替案として示したのは、単一スコアの代わりに「高次元のフィードバックチャネル」を使うという考え方です。噛み砕くと、「1つの数値ではなく、複数の観点から構造的にレビューする仕組み」ということになります。
これが最近「知識ガイド付きレビュー(knowledge-guided review)」という形で具体化されつつあります。どういうことかというと、AIエージェントが何かを出力したとき、別のAI(あるいはルールベースのシステム)が「正確性」「倫理的な問題の有無」「文脈への適合度」といった複数の軸で評価を返す、という仕組みです。1つの点数ではなく、採点表のように多面的なフィードバックをAIに渡します。
以下は、単一報酬と多次元フィードバックの違いを整理したものです。
| 観点 | 単一報酬関数 | 多次元フィードバック |
|---|---|---|
| 評価の粒度 | 1つの数値 | 複数の軸ごとにスコア |
| 得意なタスク | 数学・コード(正誤明確) | 文章・会話・判断(文脈依存) |
| 報酬ハッキングのリスク | 高い | 軸が多いため操作しにくい |
| 設計の難しさ | 比較的シンプル | 評価軸の定義が難しい |
| 現在の主流企業 | DeepSeek GRPO等 | 各社が開発中 |
この構造はまだ「開発中」です。どの企業も汎用的な解を出せていない。ただ、方向性は共有されつつあります。
ビジネス現場で働く会社員への影響
この話が「AIの研究者の話でしょ」で終わらないのは、私たちが日常的に使うAIツールの精度に直結するからです。
経理部門の担当者が月次レポートのコメント文をAIに書かせているとします。今のAIが時々「それっぽいけどどこかズレた文章」を出力するのは、まさに報酬関数の問題が一因です。流暢に見えるが内容が薄い、あるいは正確だが文脈と噛み合っていない——こういった出力は、単一スコアで最適化された結果として生まれやすい。
多次元フィードバックが実装されてくると、AIの出力が「流暢さ」だけでなく「業務文脈への適合度」「指示の意図との整合性」でも評価・調整されるようになります。結果として、業務用途での精度が上がります。具体的にいつ、どのツールに反映されるかは不確定ですが、OpenAIやAnthropicが研究の重点をここに置いている以上、1〜2年のスパンで体感できる変化になる可能性は十分あります。
プロンプトの書き方ガイドでも触れているように、今のAIへの指示は「評価軸を自分で明示する」ことが有効です。「正確さと簡潔さを両立して」「専門用語は使わずに」といった複数の制約を指示に含めることで、多次元フィードバックに近い効果を手動で作り出せます。AIの進化を待ちながら、自分の使い方も少しずつ変えていく、というのが現実的な対処です。
研究の最前線が教えるAI活用の次の一手
今回の話の構造を整理すると、AIの精度向上に使われてきた強化学習が、複雑なタスクでは根本的な限界にぶつかっており、その解決策として「評価のあり方」が見直されているということです。
これはAIを使う側にとっても示唆があります。AIに仕事を任せるとき、「良い出力かどうか」を人間がどう判断するかを事前に言語化しておくことの重要性が増しています。AIの研究者が直面している「報酬設計の難しさ」は、裏を返せば「評価基準を明確にできた人が、AIをうまく使える」ということでもあります。
AIを使った副業や業務効率化を考えている方向けのガイドでも触れているように、AIツールの精度は「何を出力させるか」だけでなく「どう評価するかを最初に決めておくか」で大きく変わってきます。カーパシーの予言が現実になりつつある今、私たちが準備できることはツールを使い始めることよりも、「良いとはどういうことか」を自分の仕事の中で言語化しておくことかもしれません。
まとめ
強化学習における報酬関数の限界は、AI研究者だけの問題ではありません。日常的にAIツールを使う会社員が「なぜAIはたまに外すのか」を理解するための、一つの核心に触れる話です。各社が多次元フィードバックという解決策に向かって動いている以上、今後1〜2年でビジネス用途のAI精度は変化するでしょう。その変化に乗るためのスキルは、技術の習得よりも「自分の仕事で何が良い出力か」を定義する力に近いところにあります。







