GoogleがリリースしたGemma 3は、8GBのRAMさえあれば手元のPCで動かせるLLMです。しかも自分のデータで追加学習(ファインチューニング)できる。社外にデータを送らずにAIを使いたいという会社員にとって、これはかなり現実的な選択肢になってきています。この記事では、Gemma 3がどういうモデルなのか、どんな人に向いているのか、そして実際にローカルで動かすには何が必要かを整理します。
「8GBで動く」は何がすごいのか
ここ数年、ChatGPTやClaudeなど高性能なAIはすべてクラウド経由でした。つまり入力したテキストは必ずサーバーに送信される。業務の数字や顧客情報、社内の議事録を気軽に貼り付けられない理由はここにあります。情報システム部門から「ChatGPTへの業務情報の貼り付けは禁止」という通達が出ている会社も少なくないはずです。
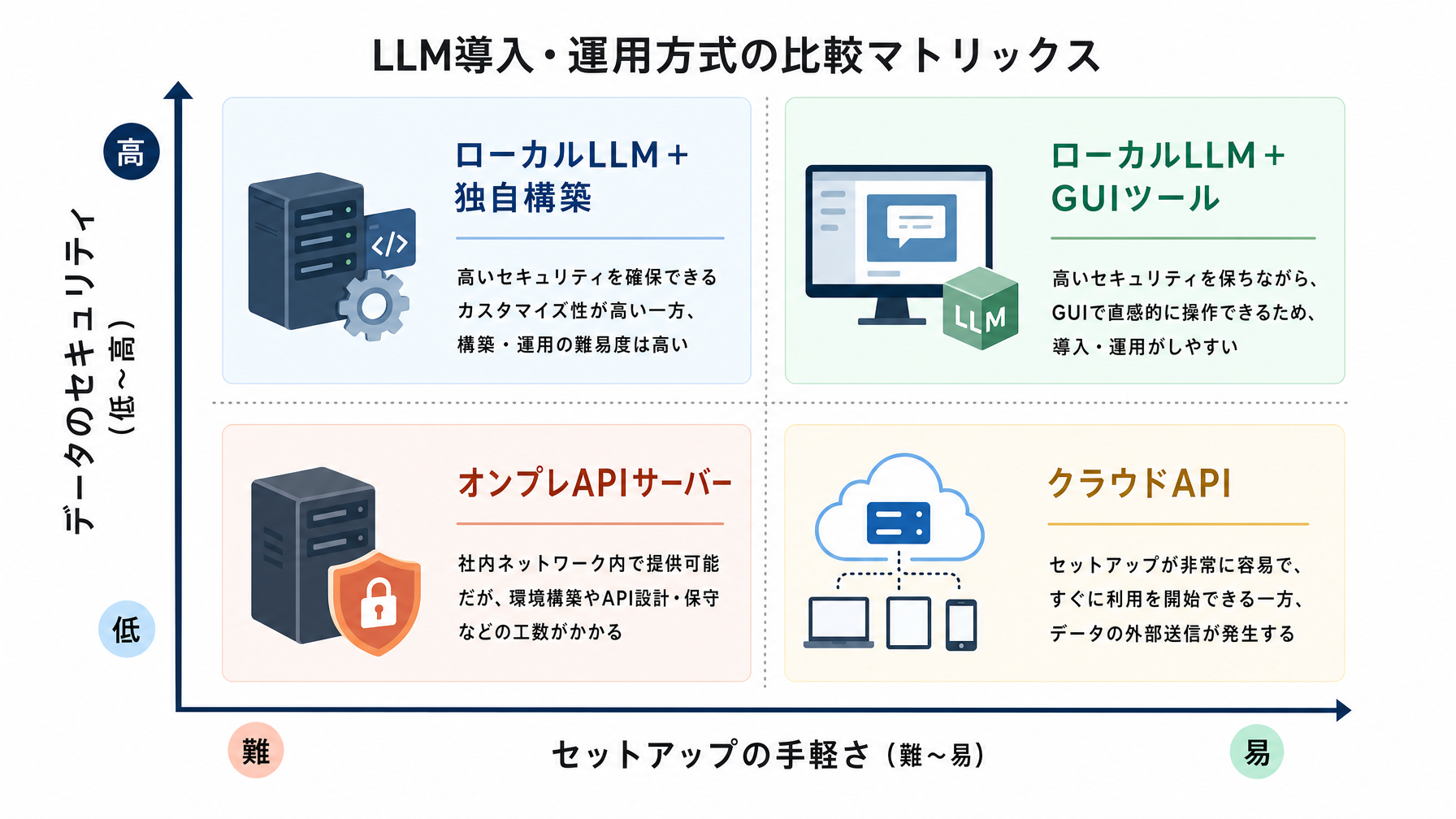
Gemma 3のような軽量ローカルLLMは、この問題を根本から変えます。モデルが自分のPC上で動くため、入力したデータが外部に出ることはありません。8GBというのは2024〜2025年時点でのミドルクラスのノートPCに標準搭載されているメモリ量で、「高性能なゲーミングPCが必要」という話ではないのがポイントです。たとえば人事部で採用候補者の評価シートを扱っている方が、そのデータをAIに読み込ませて要約や比較をしてもらうような使い方が、クラウドAPIを使わずにできるようになります。
Gemma 3の立ち位置を整理する
Gemma 3はGoogleが開発した「小型〜中型」のオープンモデル群です。GPT-4やGemini Ultraのような最大規模モデルとは違い、パラメータ数を抑えた設計で、その分ローカル実行が現実的になっています。モデルサイズはいくつかのバリエーションがあり、8GBのRAMで動くのは量子化(モデルを圧縮する技術)を施した軽量版です。
現在ローカルLLMとして話題になるモデルはいくつかありますが、それぞれに特徴があります。以下は代表的な比較です。
| モデル | 提供元 | 最小RAM目安 | ライセンス | ファインチューニング |
|---|---|---|---|---|
| Gemma 3(量子化版) | 8GB | 商用可(条件あり) | 可 | |
| Llama 3 | Meta | 8GB〜 | 商用可(条件あり) | 可 |
| Mistral 7B | Mistral AI | 8GB〜 | Apache 2.0 | 可 |
| Phi-3 | Microsoft | 4GB〜 | MIT | 可 |
この中でGemmaが注目される理由のひとつは、Googleが提供するエコシステムとの親和性です。Google ColabやVertex AIとの連携を想定したドキュメントが整備されており、学習コストが比較的低い。また日本語のトークン処理精度も改善されており、英語中心だった初期ローカルLLMに比べて日本語業務での実用性が上がっています。
ファインチューニングとは何か、なぜ重要か
モデルをそのまま使う場合、AIは汎用的な知識で回答します。しかしビジネス現場では「自社製品のFAQ形式で答えてほしい」「この業界の専門用語を正しく使ってほしい」といった要求が出てきます。ファインチューニングとは、既存のモデルに対して特定のデータを追加で学習させることで、こうした要求に応えられるよう調整するプロセスです。
非エンジニアにとっての誤解として多いのが「ファインチューニングには膨大なデータと高性能GPUが必要」という思い込みです。フルスクラッチで学習させる場合はその通りですが、Gemma 3に対してLoRA(Low-Rank Adaptation)と呼ばれる効率的な手法を使えば、数百〜数千件のサンプルデータと一般的なPC環境で追加学習が可能です。
具体的な例を挙げると、社内のカスタマーサポート担当者が「よくある問い合わせ300件とその回答」をCSVにまとめてモデルに学習させれば、自社サービス特有の質問に的確に答えるチャットボットを作れます。このデータは一切外部に出ない。セキュリティ審査なしで始められるという点は、特に中小企業や情報管理が厳しい業種にとって大きなアドバンテージです。
プロンプトの書き方を工夫することでもAIの応答精度は変わりますが、プロンプトエンジニアリングには限界もあります。自社固有の知識や語彙をモデルに「覚えさせる」にはファインチューニングのほうが適しているケースがあり、プロンプトエンジニアリングガイドと組み合わせることで、さらに精度を上げる余地があります。
実際に動かすには何が必要か
技術的な話を完全にゼロにはできませんが、2025年時点ではOllamaやLM Studioといったツールが普及しており、GUIで操作できる環境が整ってきています。最小限のハードル感をつかんでもらうために、ステップを大まかに示します。
環境の準備段階では、まず自分のPCのスペックを確認することになります。RAMは8GB以上、ストレージは10〜20GBの空きがあればGemma 3の軽量版は動きます。WindowsでもMacでも動作しますが、Macの場合はApple SiliconチップのM1以降が快適です。
モデルのダウンロードと実行は、LM StudioやOllamaを使えばコマンドラインなしで進められます。LM Studioはとくにビジュアルが整っており、ChatGPTライクなチャット画面でローカルモデルと会話できます。
ファインチューニングの実施は現時点では多少の技術的知識が必要で、PythonとTransformers/Unslothといったライブラリを使う手順が一般的です。ただしGoogleのColab(クラウド上のノートブック環境、無料枠あり)でコードを実行するだけであれば、コピー&ペーストで進められるチュートリアルも公開されています。完全なローカル実行にこだわらなければ、Colab上でファインチューニングしてモデルをダウンロードするという折衷案も現実的です。
AIを業務に使い始めたい方向けのより広い入門として、ChatGPTの使い方ガイドも参照すると、ローカルLLMとクラウドAIの使い分けイメージが具体的になります。
どんな人がGemma 3を試す価値があるか
全員がGemma 3を使うべきとは言いません。ChatGPTやClaudeのAPIで十分なら、わざわざローカル環境を構築するコストは割に合わないケースもあります。Gemma 3がとくに検討の価値があるのは、次のような状況です。
扱うデータが機密性の高い個人情報・取引先情報を含む場合、クラウドAPIの利用が社内規定で制限または禁止されている場合、月額API費用が積み上がってきており固定費化を検討している場合、あるいは自社独自の知識や文体でAIを動かしたい場合です。
逆に、使いたいのが一般的な文章作成や翻訳の補助程度であれば、ローカル環境の構築より既存のクラウドサービスをスマートに使う方が現実的です。たとえばAIを使った副業やフリーランス的な活動を検討しているなら、ローカルLLMよりもAI副業の活用方法を先に読む方が即効性があるかもしれません。
まとめ
Gemma 3の登場は「AIを使う=クラウドに情報を送る」という前提を変える可能性を持っています。8GBのRAMで動き、自分のデータで追加学習もできる。この組み合わせは、情報漏洩リスクを気にしながら「でもAIを活用したい」と思ってきた会社員にとって、一つの現実的な突破口です。ただし環境構築にはまだ一定の手間がかかるのも事実で、「自分の業務でどれだけの価値が生まれるか」を見積もってから着手するかどうかを判断するのが現実的ではないでしょうか。ローカルLLMへの関心は今後も高まっていく流れにあり、ツールの使いやすさは半年単位で改善されています。今すぐ使わないとしても、どういうものかを知っておく意味はあります。