AppleがCore AIという新しいフレームワークを公開した。これは「デバイスの外にデータを送らずにAIを動かす」という、クラウドAI全盛のここ数年の流れとは真逆のアプローチだ。ChatGPTやGeminiに慣れ始めた30〜40代の会社員にとって、これが単なるエンジニア向けのニュースで終わらない理由がある。この記事では、Core AIが何をするものなのか、なぜそれが働き方と情報管理の常識を変える可能性があるのかを整理します。
「サーバーなし・トークン代なし」が意味すること
AIを使うとき、あなたが入力したテキストや画像は通常、どこかのサーバーに送られて処理される。OpenAIならアメリカのデータセンター、GoogleならGoogleのインフラ、というかたちだ。そこで生成された回答が返ってくる仕組みを「クラウド推論」と呼ぶ。便利な反面、会社の機密情報や個人データを外部サーバーに送ることへの懸念は常についてまわってきた。
Core AIが変えるのは、この構造そのものだ。Appleのチップ(Apple Silicon)上で完結するため、推論処理がデバイスを出ない。QwenやMistralといったオープンソース系の言語モデル、SAM3という画像セグメンテーションモデルが、iPhone・iPad・Mac・Vision Proの上でそのまま動く。データがどこにも飛ばない以上、サーバーコストも発生しないし、外部サービスのAPIを叩くたびにかかるトークン課金も生じない。
これは技術的な最適化の話ではなく、「誰がAI処理を管理しているか」という主権の問題だ。クラウドAIは便利だが、データの扱いはプロバイダー側のポリシーに委ねられる。オンデバイスに移れば、その判断がユーザー側に戻ってくる。
オープンモデルがAppleデバイスで動くことの重さ
Core AIがサポートするモデルのラインアップに注目したい。QwenはAlibaba系の多言語対応モデル、MistralはフランスのMistral AIが開発した高効率な言語モデル、SAM3はMetaが公開した画像認識・セグメンテーションモデルだ。いずれも企業のクローズドモデルではなく、オープンソースとして公開されており、開発者が自由にカスタマイズできる。
これらがSwiftの数行で呼び出せるようになるということは、アプリ開発者にとっての参入障壁が大きく下がることを意味する。専用のMLインフラを持たない中小企業や個人開発者でも、デバイス上にAI機能を実装できる。日本市場向けのアプリに多言語対応のQwenを組み込む、写真アプリにSAM3で被写体を自動切り抜きする機能を追加する、といったことが現実的なコストで可能になる。
さらに言うと、モデルの事前コンパイル(Ahead-of-Time Compilation)によってロードがほぼ瞬時に完了する設計になっている。これまでオンデバイスAIの弱点だった「起動が遅い」「初回処理に時間がかかる」という問題を、アーキテクチャの段階から解決しようとしている点は見逃せない。
会社員のセキュリティ問題が変わる現実的なシナリオ
具体的な場面で考えてみる。たとえば40代の人事部マネージャーが、採用候補者の評価シートをAIで要約したいとしよう。現状では、ChatGPTなどに貼り付けた瞬間に個人情報が外部サーバーに送られる。社内ポリシーで禁止されている企業も多く、使いたくても使えないというジレンマが続いてきた。
Core AIベースのアプリが普及すれば、このシナリオが変わる。評価シートのデータがMacから外に出ることなく、ローカルで要約・分類・比較ができる。情報セキュリティ部門が許可しやすくなるし、そもそも申請不要のケースも出てくるかもしれない。「AIを使いたいが社内のコンプライアンス上難しい」という壁を、プロセスではなく技術で越えようとしているのがAppleの戦略だ。
同様に、医療・法律・金融など機密性の高いドメインでは、クラウドへのデータ送信そのものがリスクになる場面がある。オンデバイス推論が当たり前になれば、これらの業界でのAI活用のハードルが現実的に下がる。
クラウドAIとオンデバイスAIの使い分け——現時点での整理
Core AIの登場で「クラウドAIはもう終わり」という話にはならない。現時点での能力差を整理しておくことが判断に役立つ。
| 観点 | クラウドAI(GPT-4等) | オンデバイスAI(Core AI等) |
|---|---|---|
| 処理能力 | 大規模・複雑なタスクに強い | 軽〜中程度のタスクに適する |
| データの扱い | 外部サーバーに送信 | デバイス内で完結 |
| コスト | トークン課金が発生 | 追加コストなし |
| オフライン利用 | 不可 | 可能 |
| 最新情報への対応 | APIアップデートで追従 | モデル更新が必要 |
| 日本語精度 | 高い(GPT-4o等) | モデル依存で変化あり |
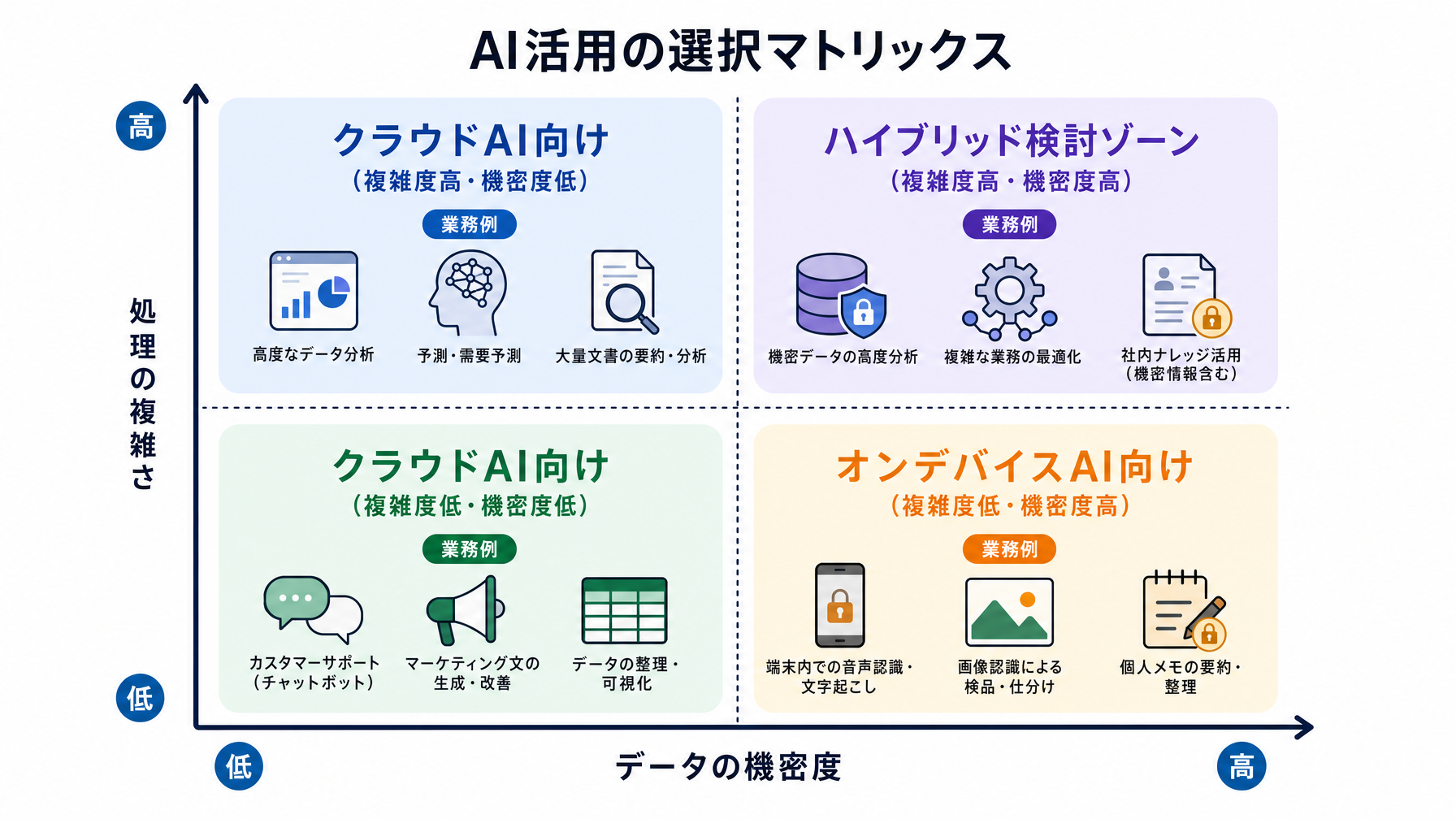
この比較を見ると、「どちらか一方」ではなく、データの機密度と処理の複雑さによって使い分けるのが現実的な姿だとわかる。社外秘の資料を扱うときはオンデバイス、複雑な分析や長文生成にはクラウド、という棲み分けが自然に発生していく可能性が高い。ChatGPTの使い方ガイドでも整理しているとおり、ツールの選択よりも「どんな情報をどこで処理するか」の判断軸を持つほうが長期的には重要になる。
Appleがオンデバイスに賭ける理由
Appleがここに注力するのには、ビジネス上の必然性がある。OpenAIやGoogleのクラウドAIサービスが強くなればなるほど、ユーザーがAppleデバイスを使う理由が「ハードウェアの質」だけになってしまう。逆に言えば、「このデバイスでなければできないAI体験」を作れれば、iPhoneやMacへの囲い込みがより強固になる。
プライバシーをブランドの中心に据えてきたAppleにとって、「あなたのデータがデバイスを出ない」は単なる機能説明ではなくマーケティングのコアメッセージでもある。Core AIはその主張を技術的に裏付ける構造だ。AI競争の文脈でAppleが「性能の高さ」ではなく「信頼性の高さ」で勝負しようとしているシグナルとして読むこともできる。
AI業界全体の動向を追いかけている方であれば、こちらのAIトレンド解説記事でも触れているように、生成AI市場はモデルの高性能化競争から「どこで・どのように動かすか」というインフラ競争に軸足が移りつつある。Core AIはその流れの中にあるAppleの一手だ。
まとめ
Core AIが普及すれば、「AIを使うこと」と「情報を外に出すこと」が必ずしも同義ではなくなる。これは、AIの社内利用をためらってきた会社員や情報セキュリティ担当者にとって、判断の前提条件が変わることを意味する。
今すぐ何かが変わるわけではない。Core AIはまだ開発者向けのフレームワーク段階であり、一般ユーザーが恩恵を受けるのは対応アプリが出そろってからになる。ただ、「クラウドに頼らなくてもAIが動く」というインフラが整い始めているいま、あなたの職場でAI利用を阻んでいる障壁がどこにあるかを改めて考えてみる価値はある。