ChatGPTやClaude、Geminiを使っていて「もう少し返答が速ければ…」と思ったことはないでしょうか。AIの回答を待つ数秒間は、業務の流れを一度止めてしまいます。その待ち時間を劇的に縮める可能性を持つ技術が、研究者たちによって精度を落とさずに8.5倍の高速化を実現したと報告されました。「投機的デコーディング(Speculative Decoding)」と呼ばれるこの手法は、AIの内側の仕組みを変えることで応答速度を大幅に改善します。この記事では、その仕組みと私たちの仕事への影響を整理します。
そもそもLLMはなぜ「遅い」のか
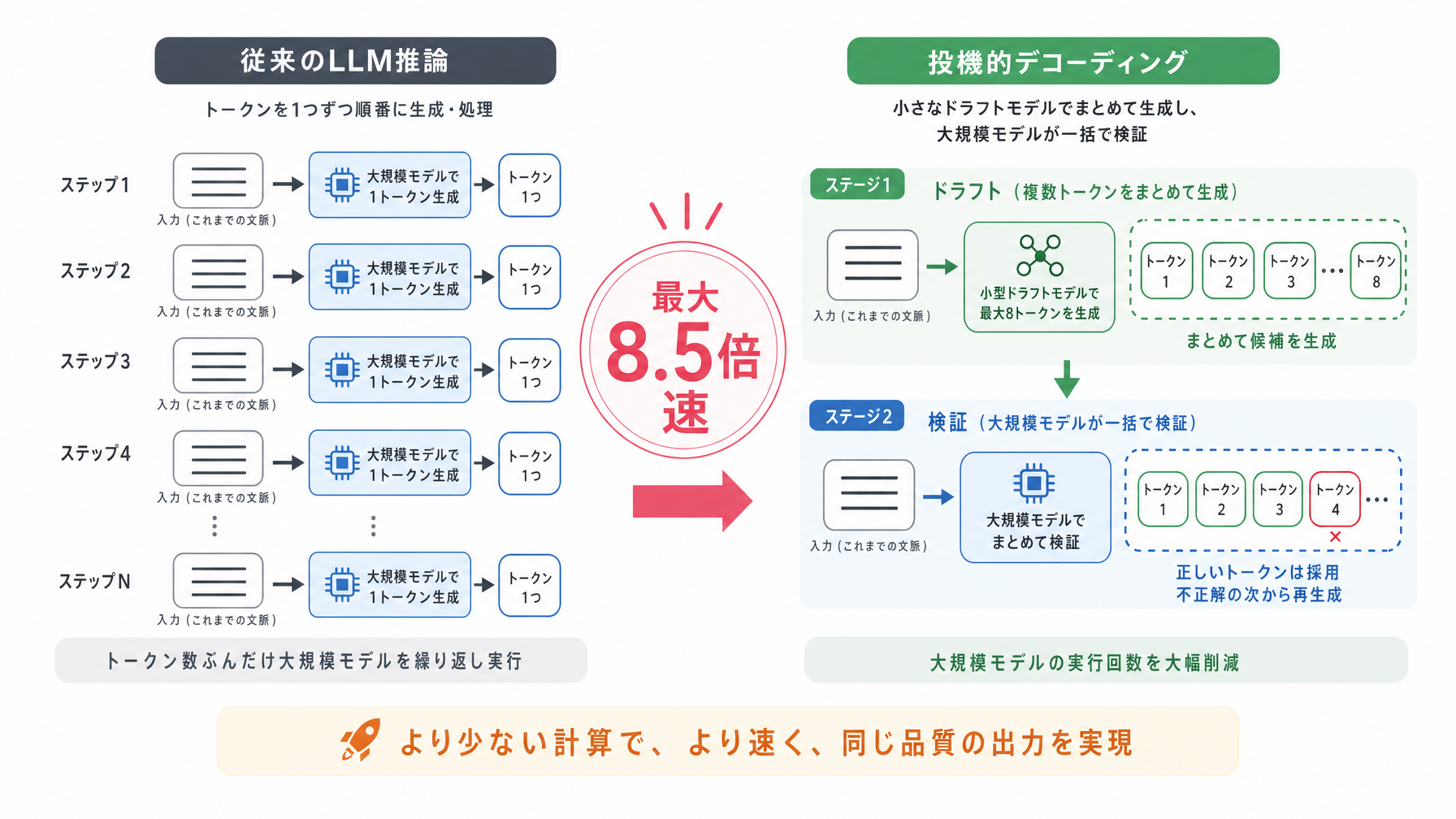
ChatGPTなどの大規模言語モデル(LLM)は、文章を一度にドバっと出力しているわけではありません。実は「1トークンずつ」、つまり単語や文字のかたまりを1つ生成するたびに膨大な計算を走らせています。「おはよう」という5文字の返答でさえ、裏側では何億ものパラメータ(数値の集まり)を使った計算が5回発生しています。これが「シングルトークンボトルネック」と呼ばれる問題で、モデルが大きいほど1回の計算コストが上がり、応答が遅くなる根本的な原因です。GPT-4のような超大規模モデルになると、この遅延は体感できるレベルになります。スマートフォンの処理速度がどれだけ上がっても、通信が遅ければページが開かないのと似た構造です。
「小さいモデルに草案を書かせる」という発想の転換
投機的デコーディングのアイデアは、ひとことで言えば「下書き係と承認係に分業させる」ことです。仕組みはこうです。まず小型の「ドラフトモデル」が、次に来そうなトークンを数個まとめて高速に予測します。これは小さなモデルなので計算コストが低く、あっという間に候補文字列を生成できます。次に本命の大型モデルが、その候補をまとめて一度に検証します。全部正しければそのまま採用し、途中で違うと判断した箇所があれば、そこより前の正しい部分だけを採用して残りをやり直す。この方式の巧みな点は、「最悪でも通常のデコーディングと同じ精度になる」という保証が数学的に成立していることです。精度を犠牲にせず速度だけを上げられる、というのが研究者たちの主張の根拠です。
8.5倍という数字はどこから来るか
今回報告された8.5倍という数字は、ドラフトモデルの精度が上がったことで「承認率」が高まった結果です。従来の投機的デコーディングの課題は、ドラフトモデルが外れを多く出すと再計算が増え、速度向上の恩恵が薄れてしまう点にありました。下の表は、ドラフトモデルの承認率と速度向上の関係を整理したものです。
| ドラフトモデルの承認率 | 速度向上の目安 |
|---|---|
| 50%程度(従来型) | 1.5〜2倍 |
| 70〜80%(改良型) | 3〜4倍 |
| 90%以上(最新研究) | 7〜8.5倍 |
この承認率をいかに高めるかが研究者たちの主戦場になっており、今回の成果はドラフトモデルの設計を改善することで承認率を大幅に引き上げた点にあります。数字自体はベンチマーク環境での計測であり、実際のサービス環境では条件によって変わりますが、それでも「精度ゼロ損失で数倍速」というインパクトは業界として無視できない水準です。
速くなると、何が変わるのか
ここで少し立ち止まって、この技術が実際の仕事にどう影響するかを考えてみます。たとえば、営業企画職の山田さん(38歳)が毎週月曜に週次レポートをAIに要約させているとします。現在は「生成中…」の画面を3〜5分眺めながら待つのが習慣になっていますが、8倍速になれば同じ作業が30秒未満で終わります。これは単に「早い」という話ではなく、AIを「待つツール」から「会話するツール」に変える質的な変化です。応答が速くなると、ユーザーはフィードバックループを短くできます。出力を見てすぐ修正を指示し、また出力を見て調整する、というサイクルを1分以内で回せるようになれば、AIの使い方自体がより試行錯誤的・対話的になるでしょう。
また、法務部で契約書レビューをしている鈴木さん(43歳)のケースも考えてみます。現在は100ページの契約書を渡すと「要注意箇所の抽出」に数分かかりますが、これが数十秒になれば、複数の契約書を連続してチェックするワークフローが現実的になります。1件ごとにコーヒーを取りに行って戻ってくるリズムではなく、連続して判断し続けられる集中の持続という観点からも、応答速度の改善は業務体験を変えます。
AIサービスへの波及はいつ、どのくらいか
研究成果が実際のサービスに反映されるまでには、通常1〜2年のタイムラグがあります。OpenAIやAnthropicといった主要AIプロバイダーはすでに投機的デコーディングの一部を実装しているとされていますが、今回のような高承認率を実現した手法の本番適用には、インフラ側の対応も必要です。一方で、オープンソースのLLMを自社サーバーで動かしている企業にとっては、この技術を独自に適用するハードルが下がってきており、ChatGPTの使い方ガイドでも触れているAPIベースの活用とは別の選択肢として注目されています。
AI応答速度の競争は、今後のサービス差別化の軸の一つになっていく可能性があります。スマートフォン登場初期に「バッテリーの持ち」が購買基準の一つだったように、「どれだけ速く正確に回答するか」が、ビジネスユーザーのAIサービス選定に影響し始めるかもしれません。Anthropicがモデル品質の透明性を競争軸にしているように、速度も単なる技術指標ではなく、ユーザーへの提供価値として語られる時代が近づいています。
「精度を保ったまま速くする」が難しい理由
コンピュータの世界では一般に、「速くしたければ精度を妥協する」というトレードオフが存在します。スマートフォンの写真処理で高画質モードにすると時間がかかるのは、まさにこのトレードオフです。投機的デコーディングが注目される理由の一つは、このトレードオフを理論的に回避している点にあります。大型モデルが最終的に「承認・却下」の判断を行う構造上、出力の品質保証は大型モデルに委ねられたままです。ドラフトモデルが外れても出力品質は落ちない、という設計は、単純に「小さいモデルに置き換える」圧縮とは本質的に異なります。プロンプトエンジニアリングの観点からも、プロンプトの書き方を工夫して質を上げる取り組みと、モデル側の高速化は補完的な関係にあります。どちらか一方ではなく、両輪として活用することで業務効率化の効果が最大化されます。
まとめ
投機的デコーディングによる8.5倍高速化は、「AIが賢くなった」という話ではなく「AIが賢さを保ったまま速くなった」という技術的な前進です。精度を犠牲にしない高速化は、AIを待つ道具から対話する道具へと変える可能性を持っています。この技術が実際のサービスに浸透するタイムラインはまだ不透明ですが、AIの応答速度を意識してツール選定をする時代は確実に近づいています。あなたが日常的に使っているAIツールの「待ち時間」が、今後どれだけ変化するか、少し意識して観察してみる価値はあるかもしれません。