
AIが「自分で実験を回す」時代が来た
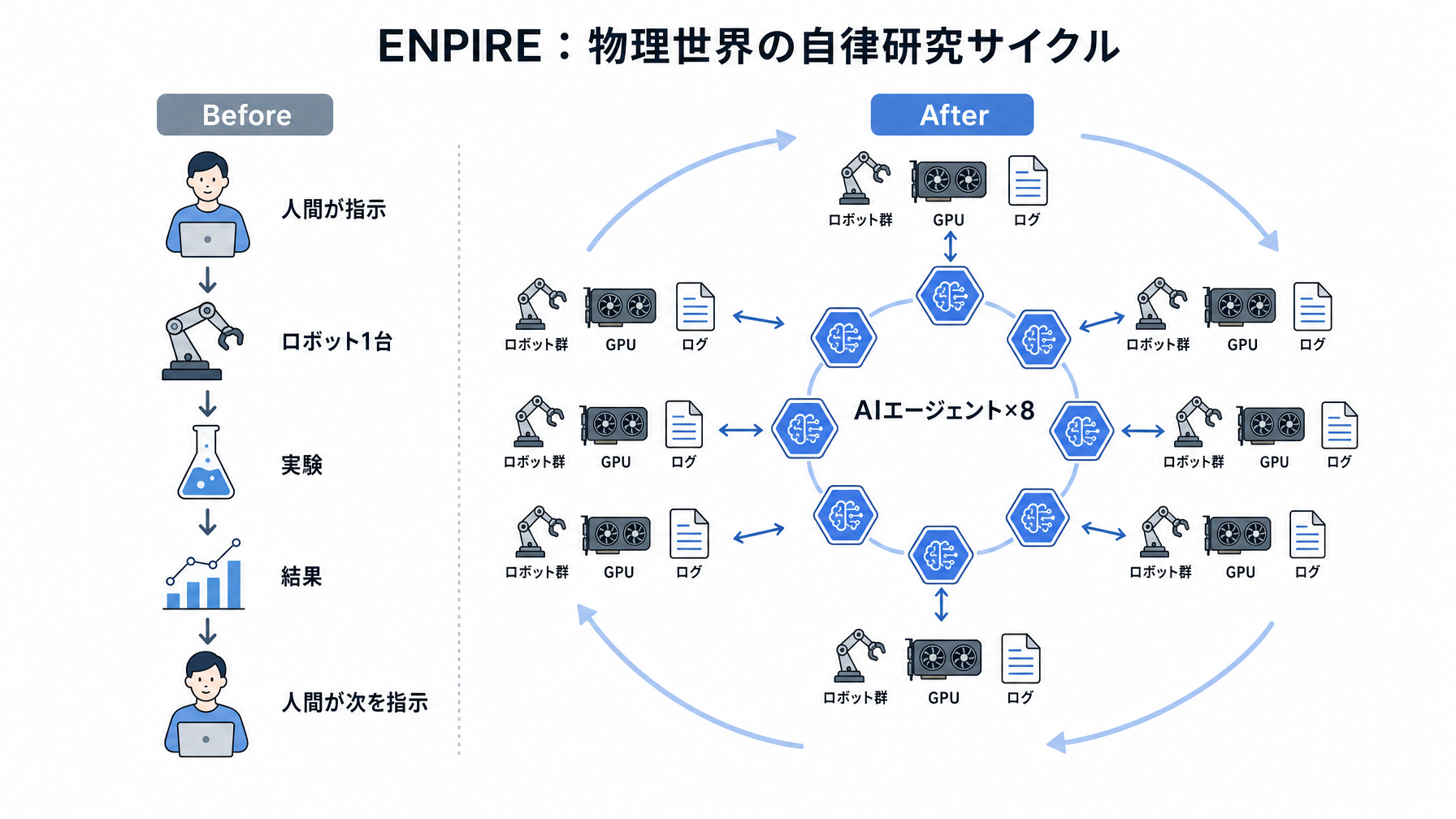
NVIDIAの研究チームが公開したENPIREというシステムが、AI関係者の間で静かに話題になっている。何がそんなに特別かというと、8つのAIエージェントがロボットの群れを自律的に操作しながら、人間の指示なしに研究課題を解き進めていくというものだ。GPUの割り当てとトークン予算だけ与えられた状態で、エージェントたちは「できるだけ速く課題を解け、ロボットを遊ばせるな、でも安全に」という大まかな目標だけを持って動き始める。
これまでのAI研究の自動化は、主にコードを書いたり文章を要約したりといったデジタル空間の話だった。ENPIREが違うのは、物理世界のロボットを動かしながら試行錯誤する点にある。カメラで視覚的な手がかりを探し、失敗したら場面をリセットし、新しい動作を練習する——これを人間が画面から離れた状態で、AIが自分たちだけで進めていく。この記事では、ENPIREが何をやっているのかと、それが私たちの仕事とどう関わってくるかを整理する。
ENPIREの仕組みを具体的に見る
ENPIREの構造はシンプルに言えば「マルチエージェントによる物理実験の自律サイクル」だ。Codexベースの8つのAIエージェントが、それぞれ役割を持ちながら並列で動く。一方が視覚情報を解析してロボットに指示を出している間、別のエージェントが実験ログを整理して次の仮説を立てる、という分業が自然に生まれる。
ここで注目したいのが「安全性の制約を自分たちで守る」という部分だ。外から常時監視する仕組みをわざと外し、エージェント自身がリスクを判断しながら動く設計になっている。これはロボット工学の文脈で言えば非常に挑戦的な選択で、これまでは「人間がいつでも止められる状態」が前提だった。ENPIREはその前提を変え始めている。
一方で、現時点では「タスクが明確に定義されている」という条件つきだ。何を解くかはあらかじめ決まっており、エージェントが自分でゴールを設定するわけではない。自律性には明確な範囲がある。この点を混同すると「AIがすべてを勝手に決める」という誤解につながるので気をつけたい。
「自律型研究」が加速する背景
なぜ今このタイミングなのか。一つには、LLM(大規模言語モデル)のコード生成精度が上がり、ロボットへの命令文を動的に生成できるようになったことがある。数年前は「ロボットにやらせたいこと」を人間がコードに落とす作業が必要だったが、今はAIがその中間作業を担える。
もう一つは、GPU性能と価格のバランスが変わったことだ。並列でエージェントを動かしながらロボットをリアルタイム制御するには相当の計算資源が必要で、これが以前はコスト面で難しかった。NVIDIAが自社システムにこの規模の計算資源を投入できることは、同社のインフラ上の強みをそのまま研究の速度優位に変換していることを意味する。
プロンプトの書き方ガイドでも扱っているように、AIエージェントの性能はプロンプトの質に大きく左右される。ENPIREの場合、エージェントへの初期目標の与え方(「速く、安全に、無駄にしない」)が非常に抽象度が高い。それでも機能するのは、Codexが持つコード生成・修正能力がかなりのレベルに達しているからだ。
会社員として「気にする必要があるか」の判断基準
正直に言うと、ENPIREが今すぐあなたの仕事に直接影響を与えることはほぼない。物理ロボットを使う研究開発の現場でなければ、来年や再来年の話でもないだろう。ただ、「AIが自律的に試行錯誤するサイクルを回す」という考え方は、デジタル業務にすでに入ってきている。
例えば、40代の製品企画担当が新機能のA/Bテストを週次で設計・分析するとする。今は「どのパターンを試すか」を自分で考えて、結果が出たら次のパターンを考える、という人間主導のサイクルだ。これが2〜3年後には、AIエージェントが複数のパターンを並列で試し、結果を評価して次の仮説を出すところまで自動化される可能性がある。ENPIREはその物理版を先に実現しているに過ぎない。
同様に、30代の社内データ分析担当がSQLを書いてレポートを作るプロセスも、ChatGPTの使い方が進化する方向性を見れば、クエリの生成と結果の解釈をエージェントが自律的にループする形に変わっていく。ENPIREを「ロボット工学の話」として切り離すより、「仕事の試行錯誤サイクルをAIが肩代わりする流れ」の延長として見たほうが実感は近い。
自律型AIシステムが持つリスクの話
ENPIREが物理世界に踏み込んだことで、これまでデジタル空間の議論だったリスクが具体的な形を持ち始める。以下の観点は現時点での課題感として整理しておく価値がある。
まず、エラーのコストが違う。デジタル空間でAIが間違えても多くの場合はやり直しがきく。ロボットが間違えると器具が壊れ、場合によっては人が傷つく。ENPIREはエージェント自身に安全判断を委ねているが、その判断がどこまで信頼できるかはまだ研究段階だ。
次に、説明責任の問題がある。人間が画面を離れている間にエージェントが意思決定を積み重ねると、「なぜこの動作をしたか」を事後に追うのが難しくなる。ログは残るが、8つのエージェントが並列で動いた場合の因果関係の再現は容易ではない。これは製造業の品質管理に関わる人にとって、将来的に無視できない問いになる。
AI副業や業務効率化を模索している人は、AI副業ガイドで触れているエージェント活用の話と合わせると、自律型システムの実務的な限界についての感覚が掴みやすいかもしれない。
日本の現場との距離感
日本でENPIREのようなシステムが工場や研究施設に入るとしたら、いくつかの条件が先に整う必要がある。安全基準の更新、導入コスト、そして「AIに任せる」という組織文化の変化だ。特に最後の文化面は、技術の普及速度に比べて遅れることが多い。
一方で、NVIDIAがこの成果を公開した意図は明確だ。Isaacシミュレーター、Omniverse、Codexを組み合わせたスタックを持つのは自社だけだという技術的な強みを、研究成果で示すことで産業パートナーへの訴求力を高めている。日本の製造業大手がこれを見てパイロット導入を検討し始めるまでの時間は、おそらく思ったより短い。
まとめ
ENPIREが示しているのは、AIの自律性が「文章を書く」「コードを直す」を超えて、物理世界で試行錯誤するフェーズに入ったという事実だ。今すぐ業務が変わるわけではないが、「人間が一度席を立てば、あとはAIが実験サイクルを回す」という設計が実証されたことの意味は小さくない。あなたの仕事の中で「毎週繰り返している試行錯誤」はどこにあるか——そこから先の自動化の話が、意外と近いところまで来ているかもしれない。







