ChatGPTに同じ説明を何度も繰り返した経験はないでしょうか。「先週話した件なんだけど」と言っても、AIには文脈が残っていない。あの不便さの根っこにあるのが、AIエージェントの「記憶問題」です。最近公開された研究論文がこの問題を正面から取り上げ、現在ある12種類の記憶システムを体系的に比較した結果、予想外の結論が出ました。この記事では、その内容を会社員の実務視点で読み解いていきます。
AIエージェントの記憶が「検索問題」でない理由
AIが何かを「覚える」というとき、多くの人はデータベースから情報を引っ張ってくるイメージを持つかもしれません。しかしこの論文が指摘するのは、エージェントの記憶はそもそも検索(リトリーバル)の問題ではなく、データ管理の問題だという点です。
検索の問題であれば、「より良い検索エンジンを作ればいい」で済みます。ところが実際のエージェントが必要としているのは、情報をどう表現してどこに保存するか(表現と保存)、何を記憶として抽出するか(抽出)、どの記憶をいつ呼び出すか(検索とルーティング)、古くなった情報をどう更新・廃棄するか(メンテナンス)という4つの層が連携した仕組みです。この区分けが重要で、単に「コンテキストウィンドウを長くする」だけでは解決しない理由がここにあります。コンテキストウィンドウの拡張は一時的なメモ帳を大きくするようなもので、長期記憶や複数のタスクをまたぐ情報管理には対応できていません。
12システムを比べた結果、「万能設計」は存在しなかった
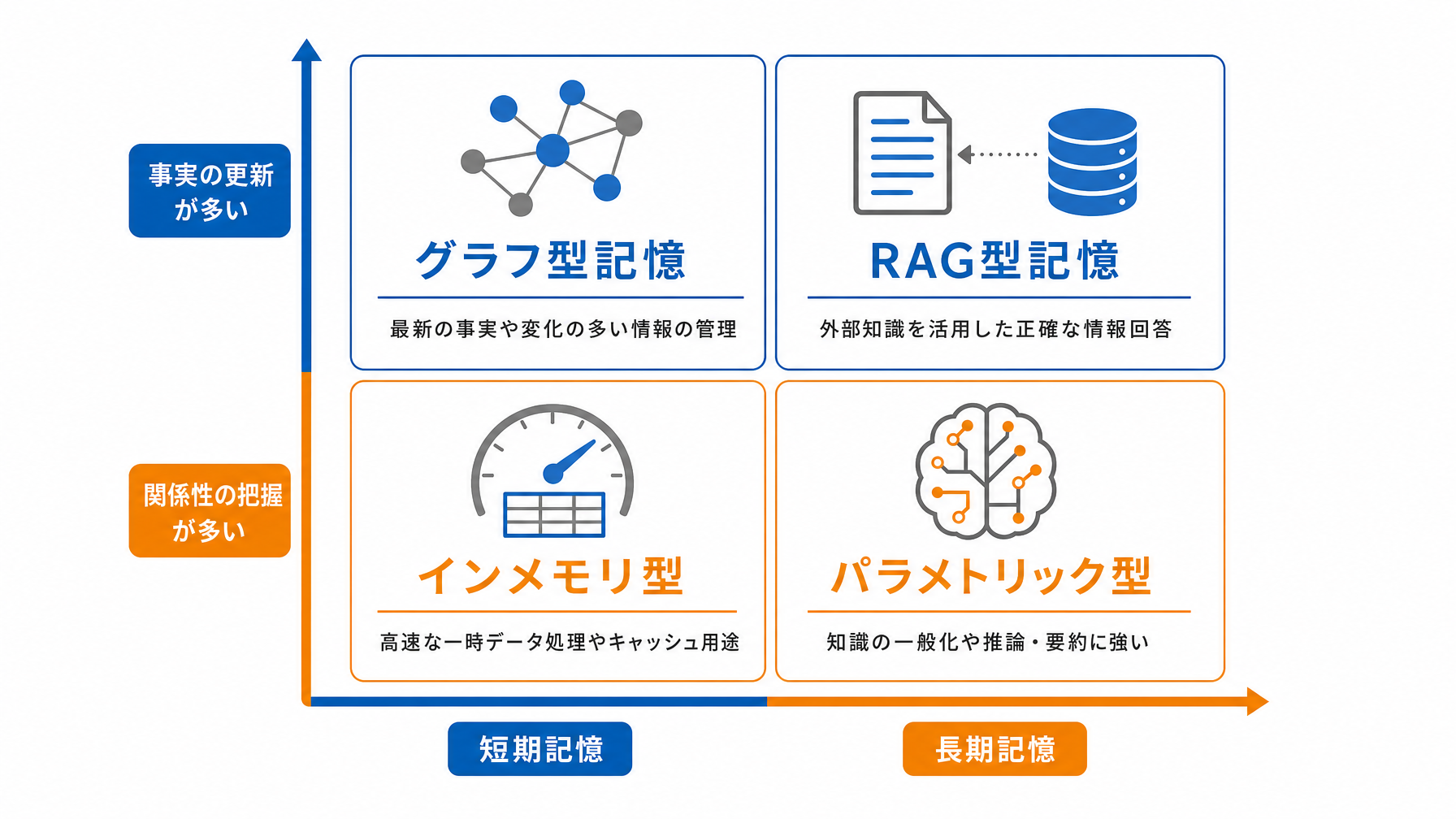
研究チームは12種類の記憶アーキテクチャを11の異なるデータセットで評価しました。その比較結果として最も注目すべきは、どの記憶設計も全領域で勝てなかったという事実です。
以下は、主な記憶タイプごとの得意・不得意をまとめたものです。
| 記憶タイプ | 得意な場面 | 弱い場面 |
|---|---|---|
| グラフ型記憶 | 事実の更新・人物や概念の関係把握 | 単純な事実の暗記・処理速度 |
| RAGベース(ベクトル検索型) | 大量文書からの関連情報取得 | 情報の更新・矛盾の解消 |
| インメモリ(短期) | 直近の会話の維持 | 長期記憶・タスクをまたいだ情報共有 |
| パラメトリック(モデル内蔵) | 汎用的な知識 | 最新情報・個人固有の文脈 |
グラフ型記憶は「田中部長が承認者で、承認フローはAプロジェクトに紐づいている」といった関係性の追跡が得意です。一方、「昨日の会議で決まった数字は1,200万円」のような単発の事実を素早く記憶・更新するのには向いていません。RAGベースの記憶(プロンプトの書き方ガイドでも触れているように、検索拡張生成と呼ばれる手法)は大量の社内文書から関連情報を引き出す場面では強いですが、「以前伝えた情報が更新されたとき」の整合性維持が課題になります。
この「万能設計なし」という結論は、裏返せば「目的に合わせて記憶システムを選ぶ必要がある」ことを意味します。エージェントの用途が異なれば、採用すべき記憶アーキテクチャも変わる。これは今後のAIツール選定に直接関わる話です。
「記憶のないAI」が職場でどんな摩擦を起こすか
少し具体的な場面で考えてみましょう。
経理部で月次の仕訳確認作業にChatGPTを活用している場面を想像してください。毎月同じ勘定科目の分類ルールを説明し直すコストは小さくありません。「消耗品費と備品費の分け方は自社ルールで10万円基準にしている」という情報を毎回入力するのは、記憶のないAIを使う限りは避けられない摩擦です。現状のほとんどのAIツールは、セッションをまたいで文脈を保持しないため、ユーザーが「記憶の代わり」を担わされています。
同様に、40代の営業マネージャーが週次の進捗レポートをAIで作成する場面でも、「うちのチームは7名で、担当エリアは関東・北陸・東海の3つ」といった基本情報を毎週説明する非効率が起きます。プロジェクト管理ツールと連携したエージェントが「チーム構成と過去の達成率の推移」を記憶していれば、レポート作成の質も速度も変わるはずですが、そのための記憶設計がまだ実用レベルに達していないのが現状です。
記憶システムの「4層構造」を理解しておく価値
冒頭で触れた4つの層(表現と保存・抽出・検索とルーティング・メンテナンス)は、AIエージェントを評価したり活用したりするときの判断軸として使えます。
「表現と保存」は、情報をどんな形式で保存するかの話です。テキストのまま保存するか、ベクトル(数値のかたまり)に変換するか、グラフ構造にするかで、後の検索のしやすさが変わります。「抽出」は、会話の中から何を記憶として残すべきかを判断するフィルタリングの仕組みです。全部保存すると逆にノイズになるため、何を覚えて何を捨てるかの設計が必要になります。「検索とルーティング」は、必要な記憶をいつ、どのタイミングで引き出すかの制御で、ここが甘いと「持っているのに思い出せない」状態になります。「メンテナンス」は記憶の鮮度管理で、古い情報が残り続けると誤った回答を生むリスクがあります。
この4層のどこかが弱いシステムは、特定の用途では使えても別の場面で破綻します。論文が「万能設計なし」と結論づけた理由はここにあります。
今後のAIツール選びに与える影響
この研究が示す方向性は、AIツールを使う側にとっても無関係ではありません。
短期的には、記憶機能をどこまでサポートしているかがAIツールの差別化ポイントになってきます。OpenAIの「Memory」機能、NotionAIのデータベース連携、各種エージェントフレームワークのメモリ実装はどれも、この4層のうちの一部に対応しようとしています。ただし現時点では、AIツールの選び方で整理したように、ユースケースによって適したツールは変わります。
中期的には、「エージェントネイティブな記憶システム」の設計がAI製品の競争軸になる可能性があります。コンテキストウィンドウの長さや推論の速さが差別化要素だった時代から、「どれだけ賢く記憶できるか」に主戦場が移るかもしれません。特にグラフ型記憶が得意とする「関係性の追跡」は、人事システムや法務ドキュメント管理のような、エンティティ間の関係が複雑な業務領域で実用的な応用が期待できます。
まとめにかえて
記憶問題を「技術的な課題」として遠ざけていると、AIツールへの期待値設定を誤ります。現状のAIエージェントが「覚えていない」のは、コンテキストが短いからではなく、記憶システムそのものの設計が業務用途に最適化されていないからです。12システムを比較した研究が「どれも完璧ではない」と結論づけた事実は、裏返せば「記憶設計の選択肢がある」ということでもあります。今使っているAIツールが何を覚えられて、何を毎回入力し直しているかを一度棚卸してみると、どんな記憶の仕組みが自分の業務に合っているかが見えてくるかもしれません。