Perplexity CEOのArav Srinivas氏が「すべての企業は、自社専用のAI評価サイクルを持つようになる」という考えを示した。技術的な話に聞こえるが、その根拠はシンプルだ。「自社しか知らない業務知識・顧客理解・ワークフロー」が、汎用AIでは絶対に埋められない差異を生むからだという。この記事では、その考え方が日本の会社員にとって何を意味するのかを整理します。
汎用AIでは埋まらない「社内知識の壁」
ChatGPTやClaude、Geminiといった汎用AIは、驚くほど多くのことができる。文章の要約も、メールの返信案も、複雑な分析の叩き台も、かなりの水準でこなす。ただ、使っていて気づくことがある。「一般論は出てくるが、うちの会社の話になると途端に頼りなくなる」という感覚だ。
これは当然の話で、汎用AIは世の中に公開された情報から学習している。一方、各社の営業ルールや、顧客とのやりとりの歴史、社内で培ってきた判断基準といったものは、どこにも公開されていない。自社の商品がどういうロジックで売れてきたか、どの顧客がどんな言い回しで動くか——こういった知識は、社外からは見えない。Srinivas氏が言う「tacit knowledge(暗黙知)」とはこのことで、この蓄積こそが企業の競争力の核だと彼は指摘する。
汎用AIが強くなればなるほど、その「一般的な賢さ」においては各社の差が縮まる。そうなると残るのは、「そのAIに何を覚えさせているか」という社内固有の部分だけになる。これは、AIが普及するほどに社内知識の価値が逆に上がるという逆転現象でもある。
「モデル→テスト→評価→改善」のサイクルとは何か
Srinivas氏の発言に出てくる「model-harness-sandbox-eval flywheel」という表現は技術寄りに聞こえるが、中身はそれほど難しくない。要は「AIに仕事をさせて、うまくいったか評価して、改善し続けるサイクル」のことだ。
具体的なイメージで説明すると、こんな流れになる。ある保険会社が契約更新の顧客対応にAIを使い始めたとする。最初は汎用モデルをそのまま使う。しかし「この顧客は3年前に一度解約しかけた経緯がある」「この業種の顧客は価格より安心感で動く」といった社内データや経験則をAIに組み込んでいくうちに、対応の精度が上がっていく。その改善の手ごたえを数字で測り、また調整する——このループを回し続けることが「flywheel(弾み車)」の意味だ。弾み車は最初は重いが、回し続けると勢いがつく。社内AI基盤とはまさにそういうものだという話だ。
「token value per watt optimization」という部分は、AIの処理コストと得られる成果のバランスを最適化する、という意味合いで、要するに「費用対効果の追求」だ。AI活用が本格化するにつれ、コスト管理の視点も経営課題になってくる。
日本の中堅企業はどこから手をつけるか
この「社内AI基盤」の考え方は、外資テック企業だけの話ではない。むしろ、長年の業界経験と顧客関係を持つ日本の中堅・大手企業にこそ当てはまる。
例えば、製造業の品質管理部門を考えてみる。検査員が年単位で積み上げてきた「このキズのパターンはラインのどこが原因か」という判断力は、マニュアルに書いていない知識の塊だ。それをAIに教え込み、若手でも同じ判断ができる仕組みを作った企業と、毎回ベテランに頼り続ける企業では、5年後に大きな差が生まれる。同様に、10年以上特定業界を担当してきた法人営業の担当者が持つ「この担当者はこういう資料の見せ方で動く」という感覚も、社内資産として捉えられる。
以下は、社内知識をAIに組み込みやすい業務カテゴリを整理したものだ。
| 業務カテゴリ | 社内固有の知識の例 | AIへの組み込み方 |
|---|---|---|
| 法人営業 | 顧客ごとの購買パターン、過去の提案履歴 | RAG(社内文書検索)+商談ログの学習 |
| カスタマーサポート | よくある問い合わせの背景にある顧客心理 | チケット履歴を使ったファインチューニング |
| 品質管理 | 不良品の判断基準・過去の不具合パターン | 画像認識+過去データの組み合わせ |
| 人事採用 | 自社で活躍した人材の行動特性 | 面接記録・評価データの構造化 |
| マーケティング | 自社顧客が反応するコピーの傾向 | A/Bテスト履歴の分析 |
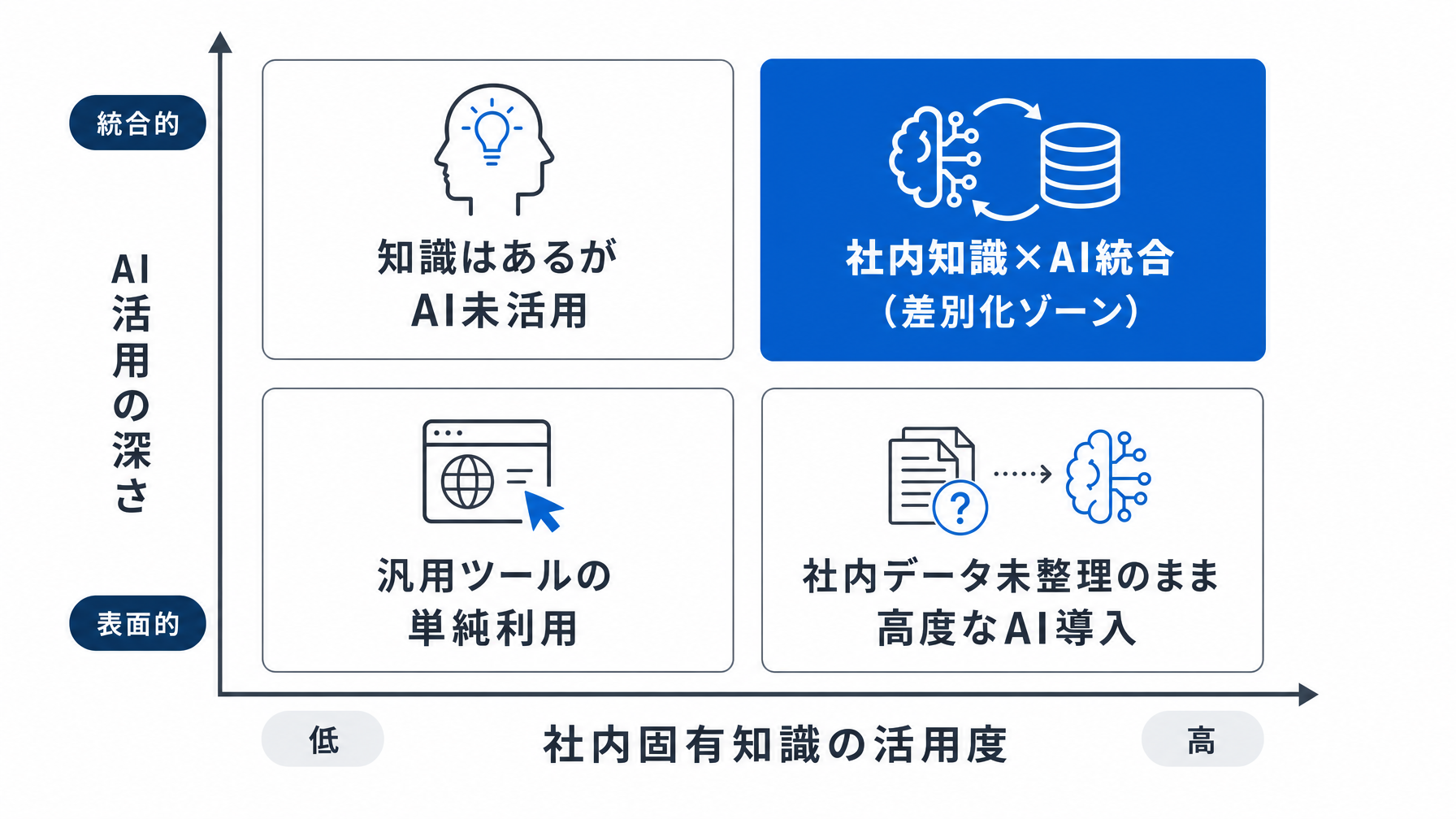
この表を見ると、「データはあるが整理されていない」という状況が多くの日本企業に当てはまることに気づくはずだ。散らばった社内ドキュメント、Excelで管理された顧客情報、引き継ぎ資料に埋もれたノウハウ——これらを構造化してAIに読ませることが、最初の一歩になる。プロンプトの書き方ガイドで触れているように、AIへの指示の精度はインプットの質に大きく依存する。
「社内AI基盤」を持つ企業と持たない企業の分岐点
2024年から2025年にかけて、日本でも大手企業によるAI活用の事例が増えてきた。ただし、「とりあえずChatGPTを全社導入しました」という段階と、「自社データを組み込んだ専用のAIワークフローを構築しています」という段階では、得られる成果がまったく異なる。
汎用ツールを全社展開した場合、最初の1〜2年は生産性が上がったように見える。文章作成が速くなる、情報収集が楽になる、といった効果は確かにある。ただし、競合他社も同じツールを使っているなら、その効果は業界全体で均一化される。差別化につながらない。一方、自社のデータと業務ロジックをAIに組み込んだ企業は、時間をかけるほど「うちにしかできないAI活用」が蓄積されていく。Srinivas氏のいう「弾み車」効果だ。
日本でAIを使った業務改善を検討しているなら、ChatGPTの使い方ガイドで基本的な使い方を押さえたうえで、次のステップとして「自社データをどう活用するか」を考えるのが現実的なルートだ。最初から高度なシステムを組む必要はなく、Notionや社内Wikiへのアクセス権をAIに与えることから始めるだけでも、汎用AIとは違う体験が得られる。
「専門家AIを育てる」という発想の転換
ここまで読んで、「でも自分は技術者ではないので、AI基盤の構築なんて関係ない」と思った方もいるかもしれない。ただ、この流れで重要になるのは、エンジニアリングの能力よりも「自社の何を知識として持っているか」を言語化できる人材だ。
30代の営業マネージャーを例に考える。彼女が10年かけて積み上げた「このクライアントは月末に連絡すると反応が良い」「提案書のページ数は5枚以内じゃないと読まれない」「価格交渉では最初に納期の話をすると決まりやすい」といった経験則は、チームには伝わっていないことが多い。これを整理してドキュメント化し、AIに読ませることで、チーム全員が彼女と同じ判断基準を持てるようになる。技術の話ではなく、知識の整理と言語化の話だ。
AI副業の入門ガイドでも触れているように、AIを使いこなすスキルの中核は「自分が知っていることをAIに正確に伝える力」にある。これは、会社員としての経験が長いほど有利な分野だ。
まとめ
「すべての企業は自社専用のAI評価サイクルを持つ」という考え方は、技術の話である前に「何が競争力になるか」という経営の話だ。汎用AIの性能が上がるほど、企業間の差は「AIに何を教えているか」に収束していく。そしてそれは、技術力よりも社内に蓄積された経験と知識の量に依存する。
あなたの会社に、他社には絶対にわからない「うちならではのやり方」はどこにあるか。その棚卸しこそが、AI時代における最初の実務課題になりつつある。