
Andrew Ngが新しいコースを公開した。テーマは「画像・動画を生成するAIエージェント」——しかも、そのエージェントが自分の出力を自ら評価し、品質を反復改善するという仕組みを学ぶ内容だ。この動きは単なる学習コンテンツの話ではなく、AIが「生成→判断→修正」を自律で回せるフェーズに入りつつあることを示している。この記事では、その仕組みの概要と、なぜ今ビジネスパーソンがこの流れを把握しておくべきかを整理します。
「生成して終わり」から「生成して自分で直す」へ
これまでの画像生成AIは、プロンプトを入力すると結果が出てくる「一発出力」が基本だった。うまくいかなければ人間がプロンプトを書き直し、また試す。この作業は思いのほか手間がかかる。マーケティング担当者がキャンペーン用のビジュアルを生成しようとしたとき、ブランドカラーがずれていたり、テキストが読みにくかったりするたびに人間が介在しなければならなかった。
今回のアプローチは、その「人間の介在」をエージェント自身に担わせるという発想だ。生成した画像に対して、エージェントが「プロンプトの内容と合っているか」「ブランドガイドラインを満たしているか」を複数の手法で自動採点し、スコアが基準を下回れば自ら再生成を試みる。このループが回ることで、人間がチェックする前にある程度の品質担保が済んでいる状態が作られる。
3つの評価手法が組み合わさる仕組み
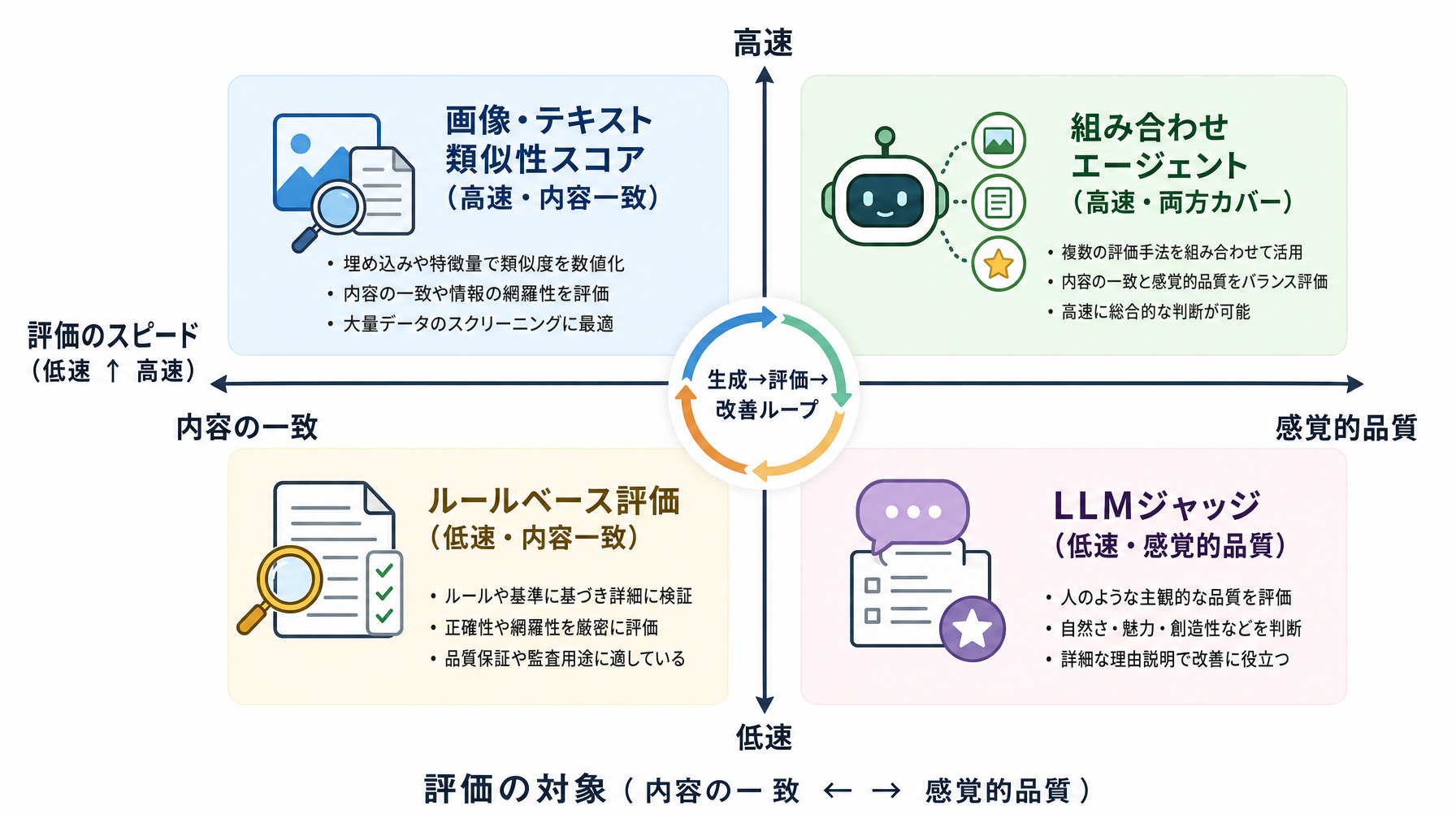
コースで紹介される評価手法は3種類ある。それぞれの役割を理解すると、なぜ組み合わせが必要なのかが見えてくる。
1つ目は「画像とテキストの類似性スコアリング」だ。これは、生成された画像がプロンプトの内容と意味的にどれだけ一致しているかを数値化する。「新緑の森の中でリラックスする人物」というプロンプトに対して、都市部の写真が出てきてしまった場合にそれを検知できる。
2つ目は「LLMジャッジ」と呼ばれる手法で、大規模言語モデル(テキストを扱うAI)が「ブランドの一貫性」や「ターゲット層への訴求力」といった、数値化しにくい基準で画像を評価する。人間の感覚に近い「文脈的な評価」ができるのがこの手法の特徴だ。
3つ目は動画特有の評価手法で、フレーム間の一貫性や動きの自然さを検出するものとみられている。静止画と異なり、動画は「時間の流れ」も品質要素に含まれるため、専用の評価軸が必要になる。
この3手法を単独で使うのではなく、エージェント内で組み合わせて運用することが、このアーキテクチャの核心になっている。一つの手法では拾えないエラーを、別の手法が補完するという設計だ。
なぜ「画像・動画生成AIエージェント」が今注目されるのか
生成AIの活用が進む中で、画像や動画の自動生成はビジネス現場での需要が急速に高まっている。しかし、品質のばらつきという課題がずっと解決されていなかった。プロのデザイナーが最終確認しなければ使えない、という状態では、コスト削減やスピードアップの恩恵を十分に受けられない。
自己評価ループはこの障壁を下げる技術として機能する。たとえば、ECサイトの商品画像を量産するケースを考えてほしい。数百点の商品について、背景の統一感、テキストの視認性、ブランドカラーの適用——これらをすべて人間がチェックするのは現実的ではない。エージェントが自律的に「これは基準を満たしている」「これはやり直し」と判断できれば、人間の確認作業は「最終的な例外処理」だけに絞れる。
Google Cloudとの共同開発という点も見逃せない。インフラ規模で支えられたエージェント設計が前提になっていることは、このアーキテクチャが個人の実験用途ではなく、企業の本番運用を意識していることを示している。
会社員が「今の自分の仕事」に引きつけて考えると
「エージェントが自律で画像を評価する」という話は、エンジニア向けの技術論に聞こえるかもしれない。しかし、この仕組みが普及したとき、実際に影響を受けるのはデザインや映像を「発注」している側の人たちだ。
広報担当の40代の管理職を例に取ると、現在は社内外のデザイナーに依頼して、修正ラウンドを重ねながら最終的な素材を確定するというプロセスが一般的だ。この「修正ラウンド」の一部が、自己評価型エージェントによって自動化されると、最初の人間へのフィードバックが「ゼロからではなく、ある程度整った状態から」になる。依頼する側にとっては、修正回数の削減という形で恩恵が現れる。
あるいは、人材採用担当者がSNS用のリクルート動画を量産しなければならない状況を想像してほしい。各拠点の雰囲気を伝える短い動画を、ブランドガイドラインに沿って10本・20本と作る場合、今は撮影・編集の外注コストと時間がかかる。自己評価ループを持つ動画生成エージェントが実用水準に達した場合、このタスクのコスト構造は根本的に変わる可能性がある。
評価技術の習得が次のAIスキルになる
AIを使いこなすスキルとして、プロンプトの書き方が注目されてきた。プロンプトの書き方ガイドでも触れているように、「どう頼むか」がAIの出力品質を左右するのは今も変わらない。しかし、自己評価ループの普及が進むと、「何を基準に評価させるか」を設計する能力がその次のスキルとして浮上してくる。
LLMジャッジに「ブランドの一貫性」を評価させるとき、その評価基準をどう言語化するか——これは本質的にはプロンプト設計の問題だ。品質基準を曖昧なまま渡してしまうと、エージェントは「なんとなく合格」を量産する。一方、評価基準を具体的に定義できれば、エージェントは人間の意図を代理で実行できる精度が上がる。
ここで重要なのは、この能力がエンジニア専用ではないという点だ。「うちのブランドとして何がOKで何がNGか」を一番よく知っているのは、現場のマーケターや営業企画の担当者だ。その知識をAIが評価できる形に翻訳できる人材が、AIエージェント時代の「使いこなし人材」になっていく。
以下に主要な評価手法の比較を示す
| 評価手法 | 何を評価するか | 得意な用途 | 限界 |
|---|---|---|---|
| 画像・テキスト類似性スコア | プロンプトとの意味的な一致 | 内容の「ズレ」検出 | 感覚的な品質は評価できない |
| LLMジャッジ | ブランド基準・文脈的な品質 | 定性的な基準の自動採点 | 評価基準の言語化が必要 |
| 動画フレーム一貫性 | 時間的な自然さ・整合性 | 動画の品質担保 | 計算コストが高い |
この3手法を組み合わせることで、それぞれの盲点を補い合う設計が可能になる。単一の評価軸に頼ると、ある基準は満たすが別の基準では低品質、という状態を見逃しやすい。
まとめ
AIエージェントが画像・動画を自律生成し、自分で評価して改善する——この仕組みは、AIを「使う人」と「作る人」の境界線を再定義しつつある。今すぐコードを書けなくても、「何を品質基準として定義するか」を考えられる人が、このシフトの恩恵を受けやすい側に立てる。あなたの職場で「品質の基準を持っているのに、それがまだ言語化されていない領域」はどこにあるだろうか。







