
この記事で分かること
ChatGPTやClaudeと並んで存在感を増している中国発の大規模言語モデル「GLMシリーズ」。その最新版であるGLM-5.2の学習基盤が、完全なオープンソースとして公開されました。名前は「SLIME」。ポストトレーニングと呼ばれる仕上げの工程を、わずか2日で完了させたというフレームワークです。この記事では、SLIMEが何をしているのか、なぜ注目に値するのかを、AIの専門家でない30〜40代のビジネスパーソン向けに整理します。
「ポストトレーニング2日」が意味すること
AIモデルの開発には大きく2つの段階があります。膨大なテキストを読み込ませる事前学習と、その後に「役に立つ回答をする」ように磨き込むポストトレーニング。後者は人間のフィードバックや報酬設計など手間のかかる工程が多く、通常は数週間から数ヶ月かかることも珍しくありません。
GLM-5.2はこのポストトレーニングを約2日で終わらせています。しかも、同じSLIMEというフレームワークがGLM-4.5からGLM-5.1まで一貫して使い回されており、モデルのバージョンが変わるたびにゼロから仕組みを作り直す必要がない。要するに、SLIMEは「使い捨ての学習スクリプト」ではなく、GLMシリーズの屋台骨として設計された再利用可能な仕組みです。
この速度感は、資金と人材を大量投入できる巨大テック企業だけが高性能AIを作れるという常識に、少し亀裂を入れています。
SLIMEの設計思想:核を固定して、変化を外に出す
SLIMEの中心にある考え方は、強化学習(RL)の核となる仕組みを1つに固定し、モデルごとの違いはデータ生成の部分で吸収するというものです。少し分解して説明します。
強化学習には2つの動きがあります。「経験を作る」フェーズと「経験から学ぶ」フェーズです。前者では、モデルが何らかの問いに答え、その答えを採点します。後者では、その採点結果をもとにモデルの重み(内部パラメータ)を更新します。
SLIMEはこの2つのうち、「経験から学ぶ」側の計算カーネルを変えずに維持します。変えるのは「どんな問いを与えて、どう採点するか」という、経験を作る側のデータ設計です。数学問題を解かせたいなら数学的な採点基準を入れる。コード生成なら実行結果で評価する。こうしたカスタマイズをデータ生成層に押し込むことで、中核の学習ロジックを安定させたまま、異なるタスクや能力拡張に対応できる構造になっています。
これはソフトウェア開発に例えるなら、共通の処理エンジンを持ちつつ、入力データのフォーマットだけ変えれば別の業務に対応できる業務システムに近い発想です。GLMチームは「ツールを毎回作り直す」のではなく「ツールに渡すデータを変える」ことに集中しました。
オープンソース化が持つ実際の意味
SLIMEが完全にオープンソースとして公開されたことは、研究者コミュニティには明らかに大きな出来事です。ただ、「自分には関係ない」と思う前に、少し立ち止まって考えてみる価値はあります。
オープンソースのフレームワークは、それを使って独自のモデルや機能を構築しようとする開発者を引き寄せます。Metaが公開したLlamaシリーズがそうだったように、「使える土台」が公開されると、その上にアプリケーションやサービスが積み重なる速度が上がります。SLIMEを使って特定業界向けのAIを作る、という試みが中国国内外の開発チームで起きるとしたら、その成果物の一部は日本の企業環境にも届いてきます。
たとえば、法律文書の要約に特化したモデルや、製造業の品質チェックログを解析するモデルが、SLIMEをベースに構築されたとしましょう。それが2日程度のトレーニングで実用水準に達するなら、スタートアップや中小規模の開発チームにとって参入障壁は大きく下がります。ChatGPTやClaudeのAPIを使う以外の選択肢が増えるということでもあります。
プロンプトの書き方ガイドで触れているように、AIモデルの使いこなしはプロンプト設計に左右される部分が大きいですが、そもそも「どのモデルを選ぶか」という入口の多様性が広がっていくことは、ユーザー側にとって交渉力の強化につながります。
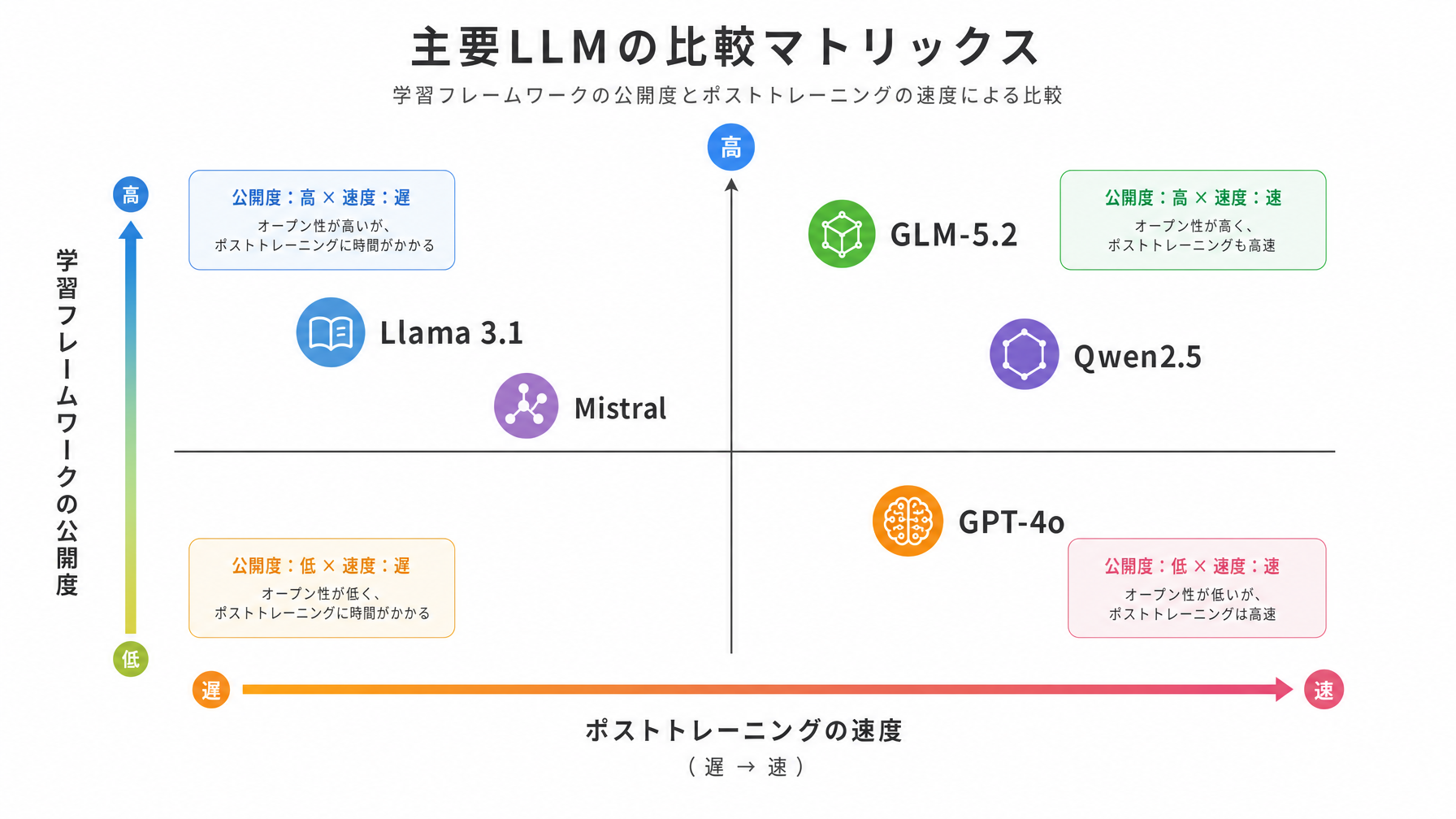
GLMシリーズと主要モデルの位置関係
GLM(General Language Model)は中国の清華大学と北京智源研究院などが中心となって開発してきたLLMシリーズです。ChatGPTの対抗馬として語られることが多い中国語圏のモデルですが、英語能力も継続的に改善されており、グローバルな評価指標でもGPT-4やClaude 3.5 Sonnetと比較されるレベルに達しています。
以下は2025年時点での主要オープンソースLLMとGLMシリーズの概要比較です。
| モデル | 公開形態 | 学習フレームワーク公開 | 主な特徴 |
|---|---|---|---|
| GLM-5.2 | オープン | SLIME(完全公開) | ポストトレーニング2日 |
| Llama 3.1 | オープン | 非公開 | Meta製、多言語対応 |
| Qwen2.5 | オープン | 一部公開 | Alibaba製、コード・数学に強い |
| Mistral Large | 一部オープン | 非公開 | 欧州発、軽量高効率 |
| GPT-4o | クローズド | 非公開 | OpenAI製、マルチモーダル |
学習フレームワークまで含めた完全公開という点で、GLM-5.2は現時点でやや踏み込んだ透明性を持っています。
会社員が「自分ごと」として読む視点
この話、エンジニアでもない会社員にとって何の関係があるのか。少し具体的に考えてみます。
たとえば、社内の問い合わせ対応を自動化したい人事部の担当者がいたとします。今は「ChatGPTのAPIを使うかどうか」という二択で考えていても、SLIMEのようなオープンフレームワークが普及することで、自社の社内規定やマニュアルを学習させた専用モデルを、外部のAPI依存なしに構築するという選択肢が現実味を帯びてきます。初期コストや技術的な難易度はまだ残りますが、「フレームワークから作る必要がない」という前提が変わるだけでも、開発のスタートラインは確実に手前に来ています。
営業企画で週次レポートの自動生成をやってみたいと思っているマネージャーの立場でも、使えるモデルの選択肢が増えることは直接的なプラスです。AIを使った仕事の効率化を考えるとき、「どのモデルを使うか」の判断材料が豊富な方が、自社の状況に合った選択をしやすくなります。SLIMEが何者かを知っておくことは、そういう意味での下地作りになります。
まとめ
SLIMEは単なる学習スクリプトではなく、GLMシリーズ全体を通じて使い回せるように設計されたRLフレームワークです。「核を固定してデータで変化を吸収する」という設計方針が、2日というポストトレーニング時間を実現しており、それが完全公開されたことで、今後の派生モデルやアプリケーションの開発速度に影響が出てくる可能性があります。
ChatGPTとClaudeの2強で語られがちな生成AI市場ですが、オープンソース陣営の整備が進むほど、日本国内での選択肢も静かに広がっていきます。あなたが今使っているAIツールの「競合になる何か」が、こういうフレームワークの上に乗って届いてくるかもしれません。







