OpenAIのエンジニアチームが、自社データ基盤で1年にわたって発生していたクラッシュ(システムの突然の停止)を体系的に調査し、2つの根本原因を突き止めました。1つはハードウェアの問題、もう1つは18年間誰にも気づかれていなかったオープンソースコードのバグです。この記事では、その調査の経緯と手法を読み解き、私たちが日々使っているAIサービスの裏側で何が起きているかを整理します。
「年1回の障害」ではなく、1年分をまとめて解剖した
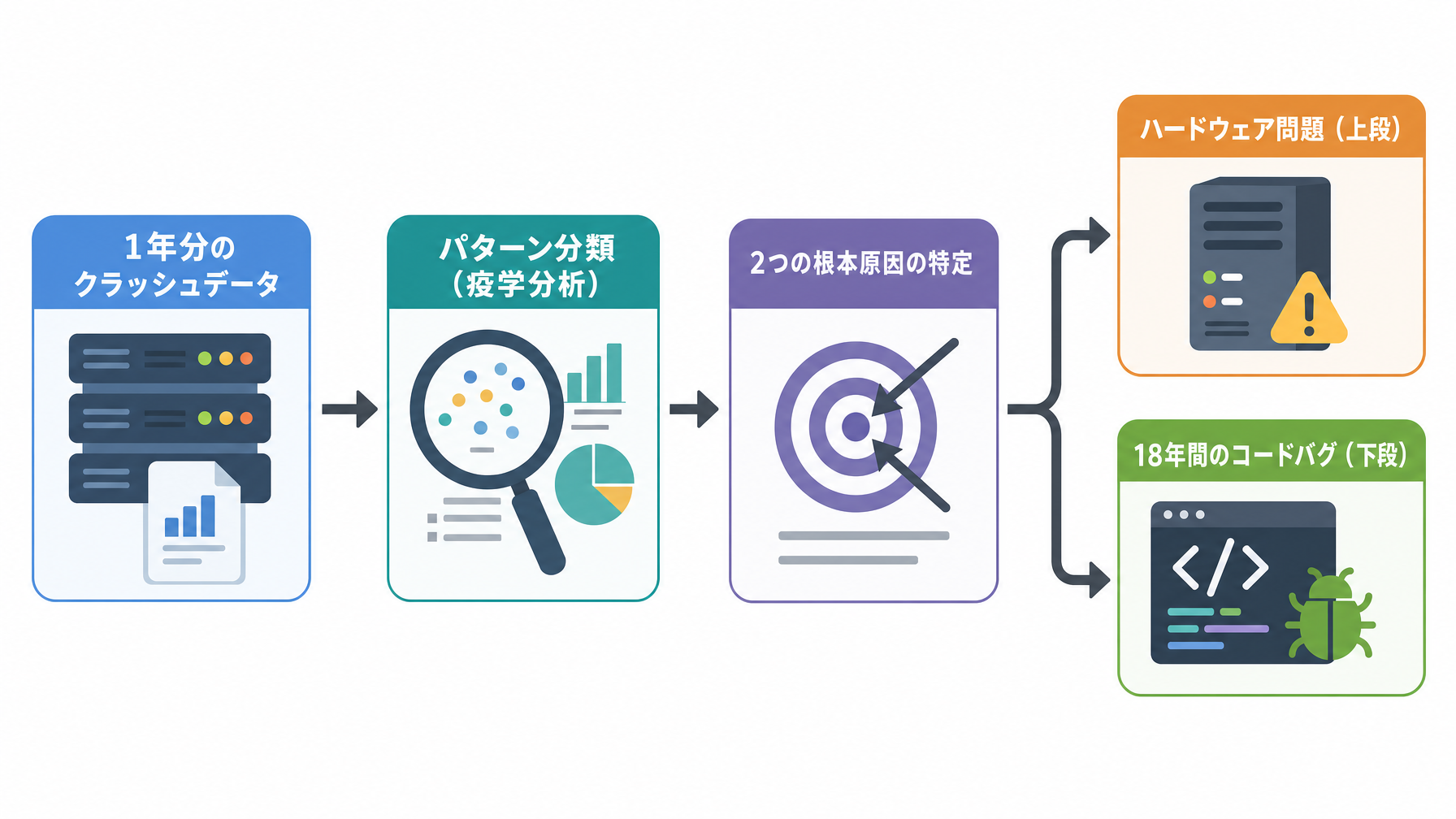
OpenAIのエンジニアが今回やったことは、日常的な障害対応とは少し違います。個々のクラッシュに毎回その場で対応するのではなく、1年分のデータをまとめて「疫学的(epidemiology)」に分析するというアプローチを取りました。疫学とは本来、感染症の広がり方を調べる医学の手法ですが、ここではシステム障害の発生パターンを俯瞰的に見る手段として使われています。
個々の障害だけを見ていると、「たまたまサーバーが落ちた」「メモリが足りなかった」程度の認識で終わりやすいです。ところが1年分のデータを並べると、特定の条件下で再現性のあるパターンが見えてきます。どの時間帯に多発しているか、どの処理が引き金になっているか、複数のクラッシュに共通するコードパスはどこか。そういった「線」が見えてくるのは、点の集積があってこそです。
2つの原因——ハードウェアとコードの「沈黙した欠陥」
調査で明らかになった原因の一方は、ハードウェア起因のものでした。詳細は公開ブログに記載がありますが、特定のサーバー群で同様の障害が集中していたことから、物理的なコンポーネントの不具合が疑われ、最終的に確認されています。これは比較的「わかりやすい」原因です。ハードウェアは壊れる。交換すれば直る。
問題はもう1つの原因です。18年間、オープンソースコードの中に潜み続けていたバグが見つかりました。オープンソースとは、プログラムのソースコードが公開されており、世界中の開発者が自由に使えるソフトウェアのことです。GitHubのような場所で管理されており、LinuxのOSからデータベース、ログ解析ツールまで、現代のITインフラのほぼすべてに何らかのオープンソースが使われています。
そのコードに2007年ごろから存在していたバグが、これまで誰にも踏まれていなかった(あるいは踏まれても原因として特定されなかった)ということは、2つの意味を持ちます。1つは、このバグを踏むような規模や条件で運用しているシステムがほとんどなかったこと。もう1つは、踏んだとしても別の原因として処理されてきた可能性です。OpenAIのデータ基盤は、一般的なシステムでは滅多に使わないような負荷や使われ方をしているため、潜在していたバグが初めて表面化した、と考えられます。
「コアダンプ」から疫学へ——調査手法の核心
OpenAIがブログで紹介した手法のタイトルは「Core Dump Epidemiology(コアダンプ疫学)」です。コアダンプとは、プログラムがクラッシュした瞬間のメモリの状態を丸ごとファイルに書き出したものです。解剖台の上に残された証拠記録のようなものと考えるとわかりやすいでしょう。
これを1年分積み上げ、共通のパターンを見つけるために統計的に分類していきます。どのスタックトレース(プログラムが何の処理をしている最中に落ちたか)が繰り返し出現するか、発生頻度に時系列のクラスターがあるか。こうした分析は、一般的なwebサービスのバグ対応でも基本となる考え方ですが、OpenAIのスケールでは1日に何百ものクラッシュが発生する環境で実施されています。件数が多いからこそ、統計的な手法が意味を持ちます。
この考え方は、実はエンジニアリング以外の場面でも応用できます。たとえば、40代の営業マネージャーが月次のKPI未達を毎月バラバラに対応しているとしましょう。毎回「担当者のフォローアップが遅れた」「商談のタイミングが悪かった」と個別対応を続けると、根本的なパターンは見えにくいままです。3ヶ月分の失注データをまとめて分類したとき、実は「初回提案から2週間以上経った案件の成約率が著しく低い」という共通パターンが見える。これが疫学的なアプローチです。
18年放置のバグが何を意味するか
18年という数字だけ取り出すと衝撃的に聞こえますが、これはオープンソースの特性と無関係ではありません。オープンソースは「多くの目で見られているから安全」と言われることがありますが、実際には「多くの目が必ずしも全コードパスを通過しているわけではない」という現実があります。
利用されるコードには偏りがあります。よく使われる機能は何度もテストされ、問題があればすぐに修正される。一方で、特定の高負荷条件下でしか通らないコードパス、ほぼ使われないオプション、あるいはマイナーなエラー処理のルートは、長年「実質的にテストされていない」状態になりがちです。今回のバグが18年間発見されなかったのは、おそらくそういう性格のコードだったからです。
OpenAIがこの発見をブログで公開したこと自体、業界にとっては意味があります。該当するオープンソースプロジェクトにフィードバックが送られれば、世界中の同じコードを使っているシステムが修正を受けられます。自社の調査結果を公開してオープンソースコミュニティに還元するという動きは、大手AI企業が技術インフラを「共有財産」として扱い始めているシグナルとも読めます。
私たちが使うAIサービスの裏側にあるもの
ChatGPTやその他のAIサービスを日常的に使っている30〜40代の会社員の視点から見ると、このニュースは「OpenAIのエンジニアの武勇伝」に見えるかもしれません。ですが、少し違う読み方もできます。
私たちが「ChatGPTが返答するまでに数秒かかった」「さっきまで使えていたのに一時的にエラーが出た」と感じる体験の背後には、こういったインフラの問題が積み上がっています。AIサービスの品質とは、モデルの賢さだけでなく、何万台ものサーバーが1年365日安定稼働するかどうかにかかっています。その安定稼働を支えるために、こういった地道な原因分析が行われているということです。
たとえば、社内でChatGPT EnterpriseやAzure OpenAI Serviceを導入しているIT部門の担当者であれば、こういった技術的な信頼性の話はベンダー選定の判断材料になります。「OpenAIはインフラの問題を公開する文化がある」という事実は、障害発生時の透明性という観点で一定の評価ができる材料です。ChatGPTを業務でどう活用するかを考えるガイドでも触れているように、ツールを選ぶ際には機能だけでなくこうしたバックグラウンドも見ておく価値があります。
「疫学的アプローチ」を自分の業務に応用するとしたら
ここまで読んで「OpenAIの話は面白いけど、自分には関係ない」と思った方に、少し別の角度から考えてみてほしいことがあります。
「1年分の問題をまとめて分析する」という手法は、実はあらゆる業務の問題解決に使えます。経理部門で毎月末に発生する転記ミスを毎回個別に修正しているとすれば、半年分のミスを集めてパターン分類するだけで「特定のフォーマットで受け取るデータが元凶」という発見につながることがあります。個別対応を積み重ねるより、定期的に「俯瞰して見る時間」を作ることで、見えてくるものがあります。
AIツールはこの「俯瞰の分析」を補助するのが得意な領域の一つです。ログやメモ、メール履歴をまとめてテキストとして貼り付け、「この中で繰り返し出てくる問題のパターンを整理して」と依頼するだけでも、自分では気づかなかった共通項が出てくることがあります。プロンプトの書き方ガイドで紹介しているような指示の仕方を使えば、分析の精度も上がります。
まとめにかえて
18年間誰にも気づかれなかったバグが、巨大なAI企業のシステムで初めて表面化する——これは決して「昔のソフトウェアはずさんだった」という話ではありません。使い方が変わり、規模が変わり、負荷の条件が変わったとき、これまで問題なかったものが問題になる。これはソフトウェアに限らず、組織の仕組みやビジネスプロセスでも起きることです。
「今まで問題なかった」という事実は、「これからも問題ない」とイコールではない。OpenAIのコアダンプ疫学の話は、そのことをあらためて考えさせてくれます。あなたの業務の中で、「18年間誰も触っていないコード」のような仕組みはどこにあるでしょうか。