
Perplexity AIが、自社のAI検索基盤を支える技術部品を外部に公開しました。対象は「Unigram tokenizer(ユニグラム・トークナイザー)」と呼ばれる処理コンポーネントで、CPU使用率を従来の5〜6分の1に削減することに成功したとしています。技術発表の文章だけ読むと「自分に関係ないな」と思うかもしれませんが、この動きはAI業界における競争の仕方が変わりつつあるシグナルとして読み解けます。この記事では、何が起きているのか・なぜ重要なのか・私たちの仕事にどう関係するかを整理します。
「トークナイザー」とは何か、30秒で理解する
AIに文章を渡すとき、AIはその文章をそのまま読んでいるわけではありません。文章をいったん「トークン」と呼ばれる小さな単位に分解してから処理します。この分解作業を担うのがトークナイザーです。たとえば「こんにちは」という文字列が「こん」「にち」「は」のような断片に分割され、それぞれに番号が振られてAIに渡されます。
この処理はCPUが担当します。一方、AIの「推論」(実際に回答を生成する処理)はGPUが担当します。GPUは非常に高速なので、推論そのものはほんの数ミリ秒で終わることもあります。ところがCPU側のトークナイザーが遅いと、GPUが完了しているのにCPUが追いつかないという状態が起きます。料理の仕込みに時間がかかりすぎて、コンロを使えない状態に近いイメージです。
なぜ今、これが問題になったのか
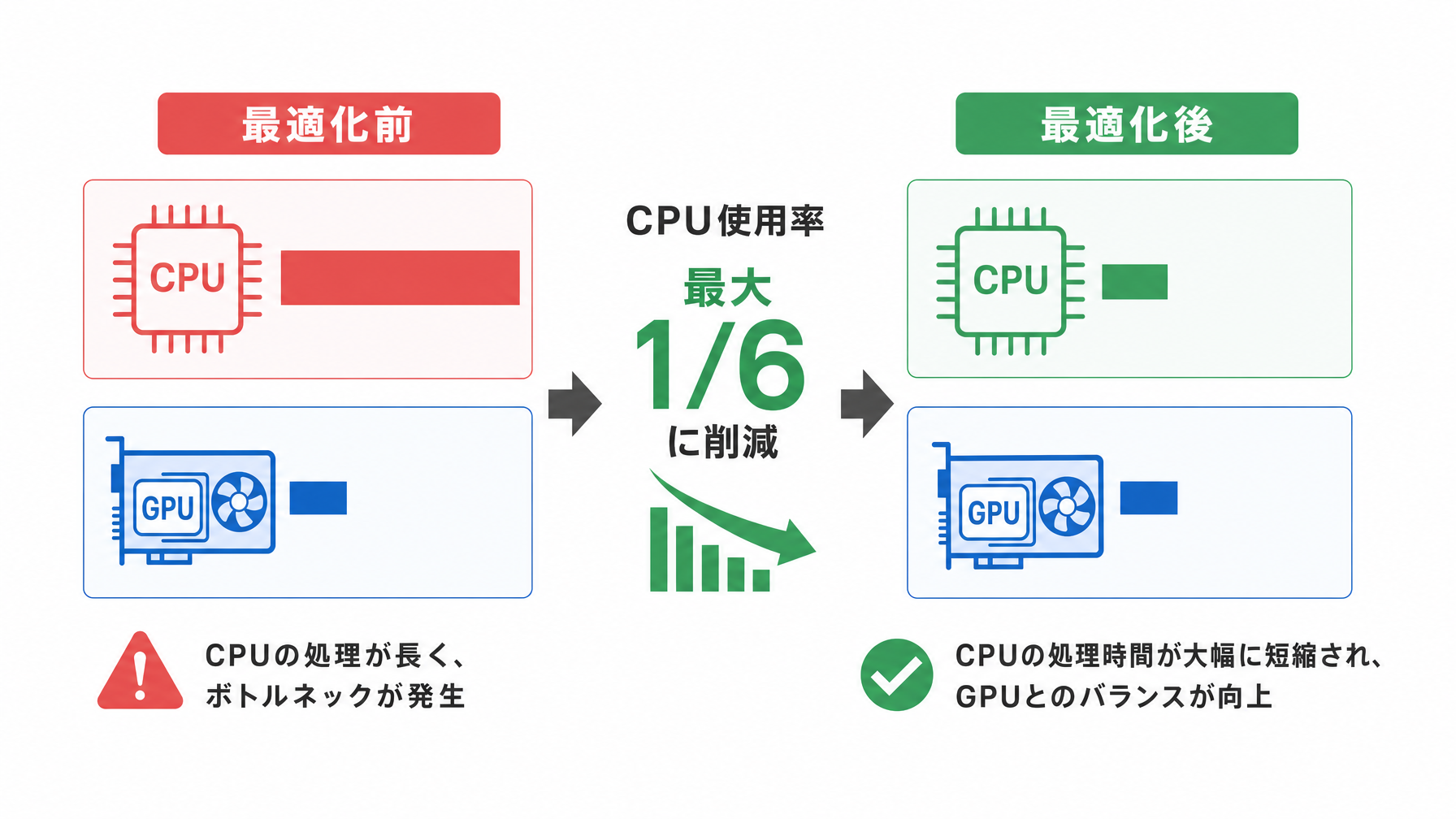
Perplexity AIが指摘しているのは、小型モデルを高速に動かす構成が普及したことで、トークナイザーの相対的な遅さが顕在化したという問題です。再ランキング(検索結果を精度高く並べ直す処理)や埋め込み(文章の意味をベクトル化する処理)に使われる小型モデルは、GPU上でシングルデジット・ミリ秒——つまり一桁ミリ秒台で処理が完了します。これほど高速になると、CPU側のトークナイズ処理がレスポンス全体の中で無視できない時間を占めるようになります。
具体的なユーザー体験で言えば、検索結果が表示されるまでの「間」の問題です。AI検索を日常的に使っている人なら、「なんとなく一瞬もたつく感じ」を経験したことがあるかもしれません。その原因の一端が、こうしたインフラレベルの処理にあります。Perplexityはその課題を特定し、トークナイザーをゼロから再実装することでCPU使用率を最大6分の1に削減しました。
オープンソース化の意味——技術公開が「武器」になる時代
Perplexityは今回の成果をGitHub(pplx-garden)で公開しました。自社が苦労して改善した技術を、なぜ無料で公開するのか。一見すると競合他社を利するだけに見えますが、実際の目的は複数あると考えられます。
開発者コミュニティからの信頼獲得という側面が大きいでしょう。AIサービスの品質を支えるエンジニアにとって、技術的に誠実な企業かどうかは採用やパートナーシップ選びの重要な軸です。また、公開することでコミュニティからのフィードバックや改善提案が集まり、自社の技術力がさらに磨かれる効果もあります。さらに、このような技術情報を発信すること自体が、Perplexityが「単なる検索ツール」ではなく「インフラ企業」として認知されることを後押しします。
AnthropicがAI安全性に関する研究を積極的に公開しているように、技術的な透明性は今や企業の競争戦略の一部です。「オープンにすることで強くなる」という方程式が、AI業界では機能し始めています。
私たちの仕事に引き寄せて考えると
ここで少し視点を変えてみましょう。今回の話は直接触れるコードの話ではありませんが、「見えない処理速度がユーザー体験を決める」という構造は、ビジネス現場でも起きています。
たとえば、40代の総務マネージャーが社内の問い合わせ対応にAI検索ツールを導入したとします。従業員が「育休の規定は?」と入力してから回答が表示されるまでの「2秒」と「0.5秒」は、体感上まるで別のツールに感じます。この違いを生むのは、モデルの賢さだけではなく、今回のようなインフラ層の最適化の積み重ねです。AIツールを選ぶ際に「応答が速い」と感じるサービスは、こうした地道な技術改善を続けている企業のものであることが多い、ということは覚えておいて損はないでしょう。
また、社内でAIツールの導入検討をしているチームリーダーにとって、ベンダー選定の際に「そのサービスはインフラの最適化を自社でやっているか、外部依存か」を確認する視点は、将来的なスケールの安定性を見極める一つの判断軸になります。
AI検索の競争軸は「賢さ」から「速さ×安さ」へ
現在のAI検索市場では、回答の精度(賢さ)はある程度どこも高水準に達しつつあります。差別化の焦点は、応答速度・コスト効率・信頼性に移ってきています。今回のトークナイザー最適化はまさに、この競争軸の変化を体現した取り組みです。
以下の表は、AI検索サービスの競争軸がどのように変化しているかを整理したものです。
| 時期 | 主な競争軸 | 差別化ポイント |
|---|---|---|
| 2022〜2023年 | 回答の賢さ | モデルの規模・精度 |
| 2024年 | 情報の新しさ | リアルタイム検索との統合 |
| 2025年〜 | 速度・コスト | インフラ最適化・小型モデル活用 |
この流れを踏まえると、Perplexityが今回やっていることは「次のフェーズの競争」に備えた基盤整備です。AI検索を業務で使っている人にとって、今後数年でレスポンスの体感速度が大きく変わる可能性があります。
AIツールの選び方や使い方について基礎から整理したい方には、ChatGPT活用ガイドが参考になります。検索AIとチャットAIの違いや、業務での使い分け方を具体的にまとめています。
まとめ
Perplexityのトークナイザー公開は、「AI企業がどこで競争しているか」を教えてくれる出来事です。モデルの賢さという表舞台から、インフラの効率という舞台裏へ。ユーザーからは見えない層での改善競争が激しくなるほど、私たちが使うAIツールの体験は静かに、しかし確実に変わっていきます。
自分が使っているAI検索ツールの「もたつき」が気になったとき、それはモデルの問題ではなく、こうしたインフラ層の成熟度の差かもしれません。ツール選びの目線を、回答の賢さだけでなく「速度の安定感」にも向けてみると、見えてくるものが変わるかもしれません。







