
AIエージェントはこれまで「本番で覚えてきた」
AIエージェントを業務に使ったことがある人なら、こんな経験があるかもしれない。「やってみたら途中でエラーを出した」「何度かやり直してようやく動いた」「そのやり直しの時間が意外と長かった」。これはエージェントの仕様上、ある意味「当たり前」の話でもあった。
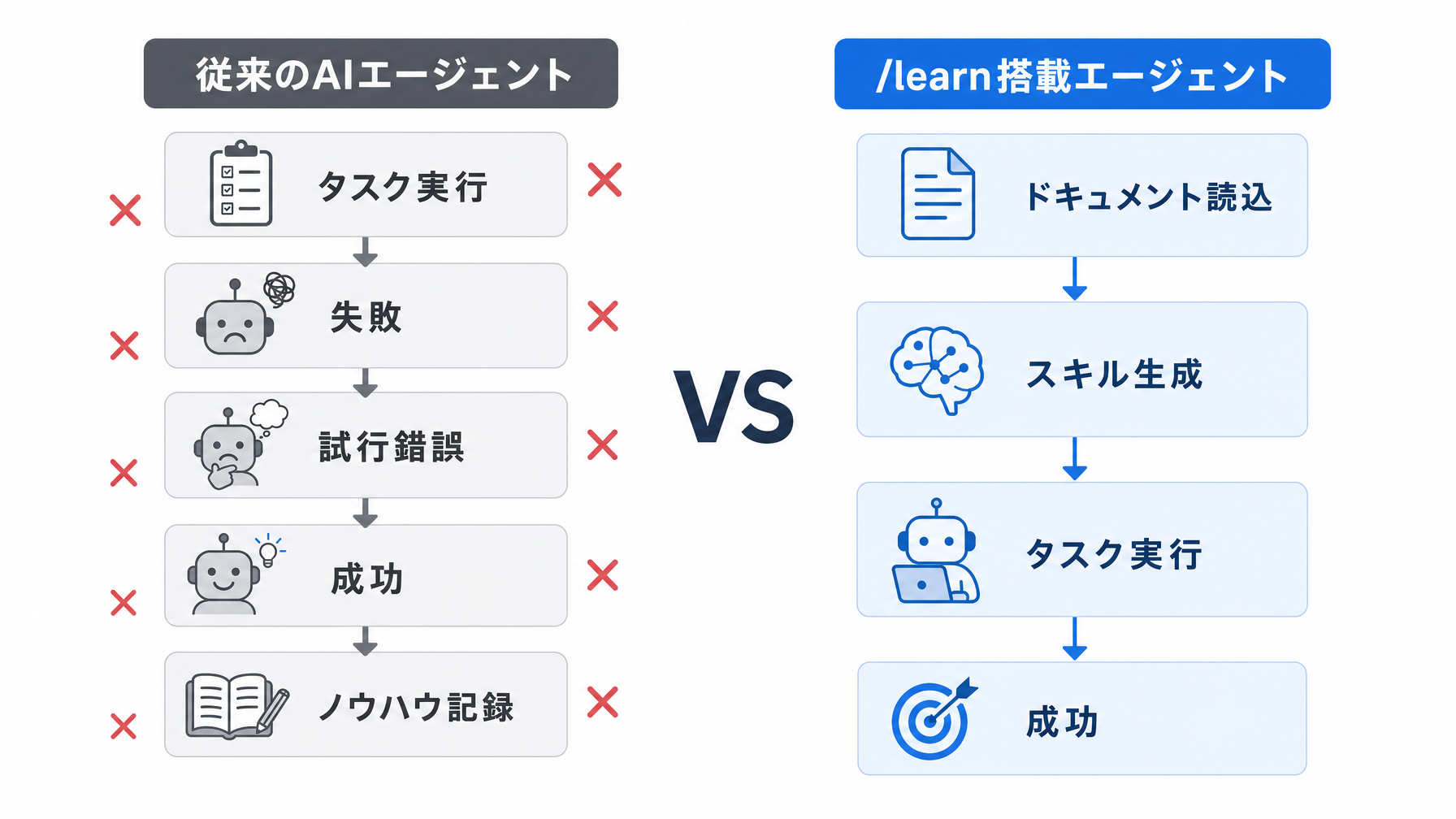
従来のAIエージェントは、タスクを実際に走らせながら試行錯誤し、うまくいかなければ別の手を探し、最終的にゴールへたどり着いた後に「何が有効だったか」を書き出す、という順番で動く。学習コストが先払いではなく、後払いになっている構造だ。言い換えれば、エージェントが「使えるようになる」前に、必ず「使えなかった時間」が発生していた。これが小さなタスクなら許容範囲だが、複雑な業務フローや外部APIとの連携が絡む場合は、その試行錯誤のセッションがそのまま担当者の残業時間に変わる。
Hermes /learn は何を変えているのか
Nous Researchが開発するHermes Agentに追加された/learn機能は、この順番をそのまま逆にする発想で作られている。タスクを実行する前に、まず「情報源を読ませてスキルを作る」というステップを挟む。
具体的には、ローカルのSDKディレクトリ、ドキュメントのURL、あるいは「自分が実際にやってみた作業の手順」をそのままHermesに渡すと、エージェントはそこから「このツールをどう使うか」「このワークフローの流れはどうなっているか」を事前に整理してスキルとして保持する。そのうえでタスクを実行するため、最初の試行から成功確率が上がる。失敗コストを実行前に払い終えている、というイメージに近い。
社内のSlack通知フローを自動化したい30代のIT担当者を例に考えると、わかりやすい。これまでは「とりあえずエージェントに投げてみる→エラーが出る→調整する→また投げる」という3〜4往復が普通だった。/learnを使う場合は、Slackのドキュメントページと社内の接続手順書をあらかじめ読み込ませ、スキルを生成してから実行に入る。最初の実行で正しい手順を踏める確率が上がるため、その3〜4往復が削れる可能性がある。
「事前学習」と「事後記録」の使い分け
/learnの登場で、AIエージェントの学習フローは大きく2種類に整理できるようになった。以下の整理は、実際の業務フローを想定したものだ。
| 方式 | タイミング | 向いている場面 |
|---|---|---|
| 事後記録(従来型) | タスク実行後 | 一度きりの作業、探索的なタスク |
| 事前学習(/learn型) | タスク実行前 | 繰り返しが見込まれる作業、外部ツール連携 |
重要なのは、どちらが「優れている」という話ではないという点だ。新しい課題を一度だけ探索するなら、従来のやり方で走らせてみる方が早いこともある。一方で、「毎月末に同じ手順で売上レポートを集計してシートに転記する」といった定型業務に近いものは、最初に/learnでスキルを作っておけば、その後の実行コストを大幅に減らせる。経理部門で同じExcel作業を繰り返している担当者なら、一度学習させたスキルを使い回す形が合っている。
「学習コスト」の分布が変わる
ここまで読んで「それって結局、最初に設定する手間が増えるだけでは」と思った方は、着目点が鋭い。確かに、/learnに渡すドキュメントや手順書を整理するのは、それなりに手間がかかる。ただ、その手間の性質が従来と異なる。
従来の試行錯誤は「エージェントが動いている間、担当者が付き合わされる時間」として発生する。途中経過を見ながら調整し、エラーが出れば対応する。この時間は他の作業と並行しにくい。対して/learn用のドキュメント整理は、非同期でできる作業だ。ドキュメントのURLを並べる、手順書を書き出す、といった作業は自分のペースで進められる。コストが「割り込み型」から「計画型」に変わる、と言い換えてもいい。
AIエージェントの費用対効果を考えるうえで、実はこの「割り込み型コストの排除」は見落とされがちな価値だ。ChatGPTの使い方ガイドでも触れているが、AIツールの活用がうまくいかない理由の一つは、「動かしながら考える」スタイルの非効率さにある。/learnはその構造に切り込んでいる。
Nous Researchという開発元について
Hermesを開発するNous Researchは、オープンウェイトのLLMファインチューニングで知られるグループだ。商用クローズドモデルが話題を集める中で、「公開・改変可能なモデルの可能性を広げる」方向で活動してきた。/learnのような機能を、エージェントフレームワーク側で実装してきた背景には、「モデルの能力だけに依存しない、使い方の設計で補う」という考え方がある。
これはAI活用の実務にも示唆がある。モデルの性能が上がれば全て解決する、という前提ではなく、「どうエージェントに情報を渡すか」「いつ学習させるか」という設計そのものが競争力になる時代に入りつつある。プロンプトの書き方ガイドで何度も出てくるテーマでもあるが、AIに何を・いつ・どう伝えるかという設計の巧拙が、アウトプットの質を左右する。/learnはその「いつ」を前倒しにした、という発明だ。
実務で使い始めるとしたら
/learnを自分の業務に取り入れる場合、まず確認したいのは「繰り返しているのに毎回うまくいかない作業があるか」という点だ。毎月使うAPIの呼び出しフロー、社内の申請システムへの入力手順、定型レポートのデータ加工プロセスなど、「またここでつまずいた」と感じる作業は候補になる。
Hermes Agentの導入自体はローカル環境でも動かせる設計になっており、クラウドにデータを送ることを避けたい場面でも使いやすい。社内情報を含むドキュメントを読み込ませる場合、情報管理の観点から「どこで処理されるか」は重要な判断軸になる。この点は導入前に確認しておく価値がある。
まとめ
/learnが提示しているのは、AIエージェントの「失敗が教師である」という前提を疑い直す視点だ。失敗から学ぶことが悪いわけではないが、その失敗を毎回本番で払う必要はない、という考え方は実務的に理にかなっている。エージェントを業務で使おうとして「試行錯誤のコストが見合わない」と感じたことがある人ほど、この設計変更は試してみる価値がある。あなたの業務の中で、「毎回同じところでつまずいている作業」はどこにあるだろうか。







