
ChatGPTやClaudeを日常的に使っている人なら、「なんかこのモデル、この手の質問は苦手だな」と感じた経験があるはずです。法律的な文言の確認はGPT-4oで、表形式のデータ加工はGeminiで、コードのデバッグはClaudeで——そうやって使い分けること自体はそれほど難しくないのですが、AIエージェントを使い始めると途端に話が複雑になります。この記事では、Nous Researchが公開したHermes Mixture of Agents(MoA)という仕組みが何を変えるのか、なぜ今注目されているのかを整理します。
1つのモデルしか使えないエージェントの限界
AIエージェントというのは、AIが自律的にツールを使ったり複数のステップを経て作業を完結させたりできる仕組みのことです。たとえば「競合他社の最新プレスリリースを調べて、自社製品との違いを表にまとめてSlackに投稿する」といった一連の作業を、人が逐一指示しなくても進めてくれます。
ただし、従来のエージェントには構造的な制約がありました。エージェントは動き出す前に「どのモデルを使うか」を1つ決めなければならず、途中で切り替える手段がほぼなかったのです。これは単なる利便性の問題ではなく、精度の問題です。GPT-4oが得意な推論タスクとClaudeが得意な長文の要約タスクが同じワークフロー内に混在していても、最初に選んだモデルがすべてを担当します。各モデルは他のモデルが気づいたはずの見落としを抱えたまま、アウトプットを返し続けます。
この問題を感じているエンジニアや先進的なAI活用者が取ってきた回避策は、同じプロンプトを手動で複数モデルに投げ、答えを突き合わせて統合する、というものでした。効果はあります。ただ、この「突き合わせ作業」はエージェントの外側で起きているため、エージェントが持っているツール接続・メモリ・セッション状態がすべてリセットされてしまいます。回り道をした瞬間に、エージェントとしての利点が消えてしまうわけです。
Hermes MoAが変えたこと
Nous Researchが公開したHermes AgentのMixture of Agents(MoA)は、この回り道をエージェントの内側に組み込みました。
仕組みの骨格はこうです。エージェントが1つのタスクを受け取ると、そのタスクを複数のモデルに並行して渡します。各モデルがそれぞれ回答を出したあと、アグリゲーター(統合役)がその回答群を見て最終的なアウトプットを生成します。モデルAが見落とした部分をモデルBが補い、モデルBが自信のない部分をモデルCが埋める——というループが、エージェントのセッションを切らずに完結します。
ここで重要なのは「セッションを切らない」という点です。エージェントが途中でWebを検索したり、スプレッドシートを読み込んだり、過去のやり取りを参照したりする能力は、セッションが継続していることで初めて成立します。従来の手動での「複数モデル突き合わせ」はこのセッションを壊していました。MoAはそれを壊さずに複数モデルの協調を実現しています。
実務での使いどころ
「それって開発者向けの話でしょ」と思うかもしれません。ただ、これが一般的なAIワークフローツールに組み込まれるとどうなるか、具体的に考えてみると話は変わります。
たとえば、マーケティング部門で市場調査レポートを週次で作成している担当者の場合。現在は「競合のWebをClaudeで要約させ、その結果をGPT-4oに渡して比較表を作らせ、最後にまた手作業でSlackに貼る」という流れで30〜40分かかっているとします。MoAが統合されたエージェントなら、要約・比較・整形の各ステップで最適なモデルが自動的に使われ、セッションを通してツール接続が維持されるため、このフローを一気通貫で処理できます。モデルの得意・不得意をユーザーが管理する必要がなくなる、というのがポイントです。
もう少し地味なシナリオも挙げておきます。法務部門で契約書の条項チェックを行っている担当者がいたとして、「曖昧な表現の指摘」と「法的リスクの評価」と「修正案の提示」では、モデルごとの得意領域が微妙に違います。現状は3つのステップを別々にモデルに投げているか、1モデルに無理やりまとめているかのどちらかですが、MoAはその使い分けをエージェント内で自動化できます。
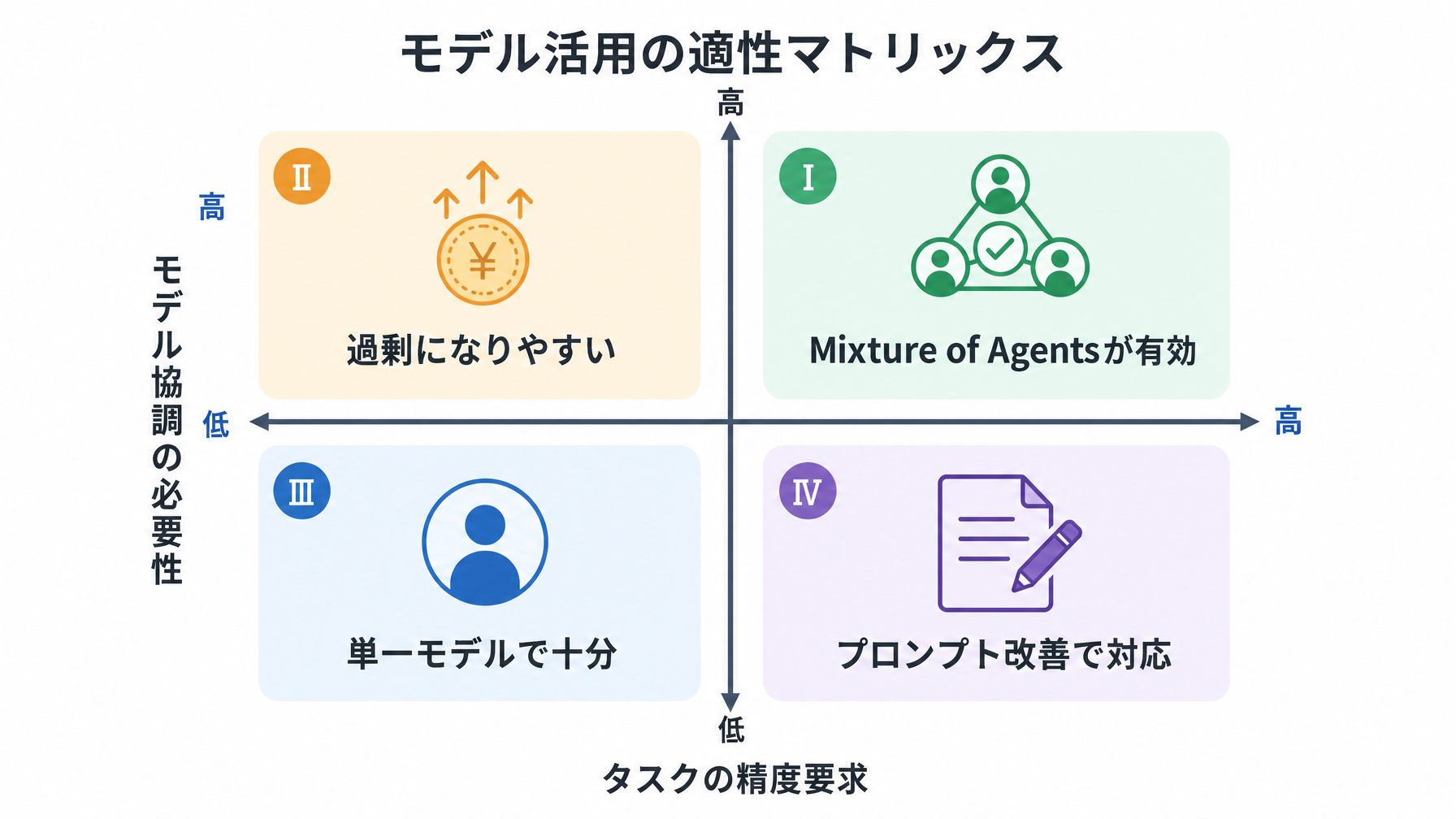
モデル協調の設計をどう見るか
以下の表は、MoAの前後でエージェント利用者が体験する変化を整理したものです。
| 観点 | 従来の単一モデルエージェント | Hermes MoA |
|---|---|---|
| モデルの死角 | 1モデルの弱点がそのまま出る | 他モデルが補完する |
| セッション維持 | ○ | ○(維持されたまま統合) |
| 手動での調整 | 必要(モデルを手で切り替える) | 不要 |
| レイテンシ | 速い | やや遅い(並行処理次第) |
| コスト | 1モデル分 | 複数モデル分かかる |
コストとレイテンシのトレードオフは無視できません。複数モデルを並行で動かすということは、APIコストが単純に増えます。スピード重視の軽量タスクにMoAを使うのは過剰かもしれません。一方、精度が求められるアウトプット——法務、財務、顧客向けの公式コミュニケーション——では、コスト増を上回る価値が出やすいと考えられます。
どのタスクにMoAを適用するかの判断軸は、「間違えたときのコスト」と「モデル単体の自信度」の2軸で考えると整理しやすいです。プロンプトの書き方ガイドで触れているように、AIへの指示設計と出力の検証設計は切り離せない関係にあります。MoAはある意味、検証のプロセスをモデル協調に任せる設計とも言えます。
Nous Researchという文脈
このMoAを開発したNous Researchは、オープンソースのLLM開発で知られる研究グループです。商業色の強い大手AI企業とは異なり、モデルの実験的な機能をオープンに公開するスタイルを取っています。Hermes自体、汎用エージェント向けに調整されたモデルシリーズで、ツール使用・長文記憶・複雑な推論の3点に注力して開発されてきました。
MoAという概念自体は学術研究として以前から存在していましたが、エージェントフレームワークに統合されて実用的に使える形になったのは比較的最近の話です。AIエージェントを業務に使い始めている企業にとっては、「単一モデルへの依存をどう下げるか」は今後数年で実務上の重要課題になる可能性があります。AIを使った業務改善の実践例でも触れているとおり、ツールの精度より「どう組み合わせるか」の設計が差を生む段階に入りつつあります。
まとめ
Hermes MoAが解決しようとしているのは、「1つのモデルを信じ切るしかなかった」という構造的な制約です。複数モデルを手動で使い分けることは今でもできますが、その作業がエージェントの外側にある限り、自動化の恩恵は半減します。MoAはその作業をエージェント内部に取り込み、ツールやメモリを失わずに複数モデルの協調を実現しました。
コストとレイテンシの問題があるため、すべてのタスクに向くわけではありません。ただ、「このモデルはここが苦手だから手作業で補っている」という作業が業務フローの中にある人は、MoAが組み込まれたツールが普及したときに何が変わるかを、今から少し考えておく価値はあります。







