Perplexity AIのCEO、アラブ・スリニバスが「複数の数兆パラメータ規模のオープンソースモデルがもうすぐ出てくるらしい」とXに投稿したのは、AIコミュニティの中では小さくない話題になりました。パラメータ数が兆の単位になるとどういう意味があるのか、そしてコストが下がったときに何が起きるのか——この記事では、その2点を軸に整理します。
「兆パラメータ」が何を意味するのか
パラメータとは、平たく言えばAIモデルが持つ「記憶の粒の数」です。GPT-3は1,750億パラメータで登場し、当時は圧倒的なサイズと言われました。それから数年で、最前線のモデルは非公開のものも含めて1兆を超える規模に達していると推測されています。一方、オープンソース——つまり誰でも無料でダウンロードして使えるモデル——の最大手はMetaのLlamaシリーズで、2024年時点では4,050億パラメータ版まで公開されています。
今回話題になっているのは、その「オープンソース」で「兆パラメータ」という組み合わせです。クローズドなGPT-4クラスの性能が、ダウンロードして自前のサーバーで動かせるようになるかもしれない——というシナリオです。これは企業にとって何を意味するかというと、APIの利用料を払わずに同等の処理能力を手に入れる選択肢が現実的になる、ということです。もちろん自社でサーバーを動かすコストはかかりますが、大量にAPIを叩いている企業にとっては試算が変わってきます。
ジェボンズのパラドックスとは何か、AIに当てはめると
「ジェボンズのパラドックス」は19世紀イギリスの経済学者ウィリアム・スタンレー・ジェボンズが提唱した概念で、「燃料効率が上がると、かえって燃料の消費量が増える」という観察です。蒸気機関の効率が改善されたとき、石炭の消費量は減るどころか増えた——なぜなら、安く使えるようになったことで新しい用途が次々と生まれたからです。
これをAIのトークン価格に当てはめると、こうなります。GPT-4の登場当初、1,000トークンあたりのコストは入力で0.03ドルほどでした。それが競争と技術改善で下がり続け、2025年時点では同クラスのモデルで10分の1以下になっているケースもあります。価格が下がったから利用量が減ったかといえば、逆です。安くなったことで、これまで「コストが見合わない」と判断されていた処理——たとえば全社メールを毎日要約するとか、大量の顧客レビューを分類するとか——が一気に現実的になりました。オープンソースで兆パラメータ級が出てきた場合、この動きはさらに加速する可能性があります。
コストが下がると何が起きるか:業務レベルで考える
抽象的な話をしても実感が持ちにくいので、具体的な場面で考えてみます。
製造業の品質管理部門で働く40代のマネージャーを例に取ります。毎月数千件ある顧客クレームの傾向を掴むために、担当者が手動でスプレッドシートに分類を入力する作業が続いていたとします。今のAPIコストでも「やれないことはない」水準ですが、月に数万円のコストが発生するため稟議が通りにくい。これがオープンソースの大型モデルを自社サーバーで動かせるようになれば、APIの従量課金なしに同じ処理が走ります。コストの壁が下がれば、「試してみよう」という意思決定のハードルも下がります。
もう一つ、マーケティング部門での例を挙げます。30代の担当者が、週に一度まとめていた競合他社のSNS投稿の分析レポートを自動化したいと考えています。現状は「毎日回すほどではないが、週次では遅い」という中途半端な状態です。コストが十分に下がれば、毎日自動で走らせて変化があったときだけアラートが上がる仕組みにできます。処理を減らすのではなく増やすことで、むしろ業務の質が上がる——これがジェボンズのパラドックスが会社員レベルで起きる形です。
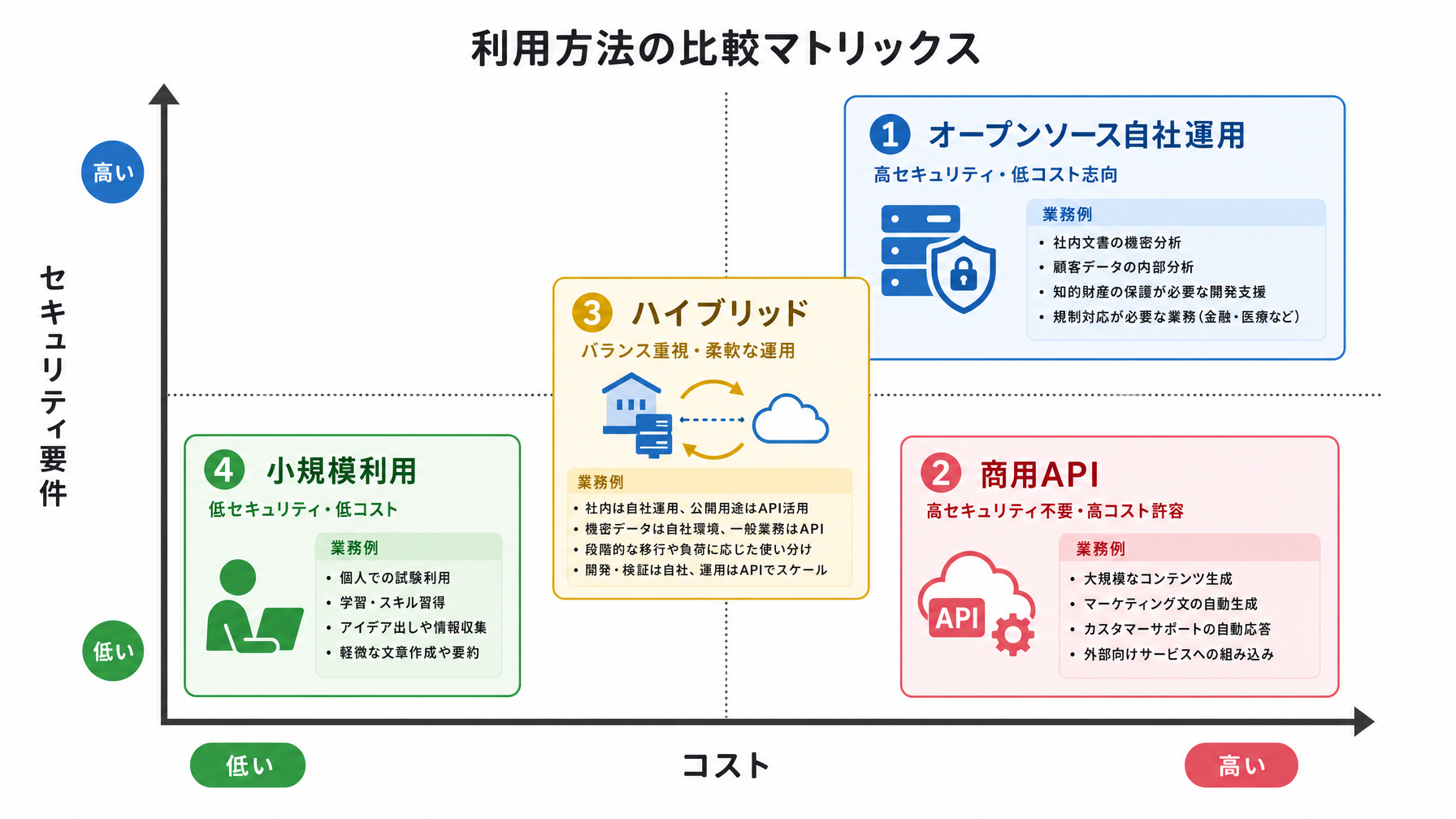
オープンソースと商用サービスの使い分け
ここで一つ整理しておきたいのが、オープンソースのモデルが強くなっても、OpenAIやAnthropicのような商用サービスがすぐに不要になるわけではないという点です。
以下は、現時点での使い分けの目安です。
| 条件 | 商用API | オープンソース |
|---|---|---|
| 社内データを外部に出せない | 向かない | 向いている |
| 最新モデルをすぐ使いたい | 向いている | ラグがある |
| コスト予測を固定したい | 向いている | サーバー費用が変動 |
| 大量処理を自社でコントロールしたい | 従量課金が積み上がる | 向いている |
| 小規模・スポット利用 | 向いている | 導入コストが割に合わない |
社内の個人情報や機密文書を扱う場合、外部のAPIに送ることへの法的・規程上のリスクを気にする企業は少なくありません。そういった用途でオープンソースの高性能モデルを自社インフラで動かす選択肢は、IT部門の担当者からすると「待っていた動き」だと言えます。一方で、個人や小規模チームが試しに使う場合、そもそもサーバーを用意するほうがコストも手間もかかるので、引き続き商用APIのほうが合理的です。ChatGPTの使い方ガイドで紹介しているような個人利用の範囲では、オープンソースの動向よりも商用サービスの機能改善を追うほうが実用的です。
「もうすぐ登場する」情報をどう受け取るか
アラブ・スリニバスの投稿は「聞いた話によると(from what I hear)」という表現を使っており、公式のリリース情報ではありません。こういった業界観測ツイートは、情報の性質として「ほぼ確実に起きる」から「業界で噂になっている」まで幅があります。
ただ、過去の動きを見ると、この種の観測が大きくはずれることは多くありません。2023年のMeta Llama 2、2024年のLlama 3のリリースはいずれも公開前に業界で話題になっており、実際に登場しています。また、Mistral AI(フランス)やDeepSeek(中国)など、Metaの独占でもなく複数のプレーヤーが大型オープンソースモデルの開発に動いている事実はすでに報道されています。「複数のモデルが近く来る」という観測は、単なる噂というより業界の文脈に沿った読みと見るほうが自然です。
AIの最新動向を追うときに役立つのが、プロンプトの書き方ガイドのような実践的な知識と並行して、こうした業界の地殻変動も把握しておくことです。モデルの性能や価格帯が変われば、プロンプトの最適な書き方も変わってくるからです。
まとめ
「兆パラメータ規模のオープンソースモデルが出てくる」という話の本質は、性能の話だけではありません。コストが下がれば使われる量が増え、使う量が増えれば新しい用途が生まれ、それがさらにコスト低下の圧力になる——このサイクルが始まる可能性を示しています。会社の中でAIの導入を検討している人、あるいは「まだ様子見でいい」と思っている人にとって、この流れは無視しにくい変化です。あなたの職場では、「コストが今の半分になったら自動化できる作業」はどこにありますか。
AIを使って副業や新しい仕事の形を探している方には、AIを活用した副業ガイドも参考になるかもしれません。